AI Summary
OpenAI has achieved a significant breakthrough in AI reasoning, with its experimental model securing a gold medal at the 2025 International Mathematical Olympiad (IMO). This marks a pivotal moment as the AI demonstrated human-level creative thinking and the ability to construct complex, multi-page mathematical proofs under strict competition conditions (two 4.5-hour sessions, no external tools, and natural language proofs). The model's success in solving five out of six problems, earning 35/42 points, highlights its advanced capabilities in sustained, intuitive mathematical reasoning, a domain previously thought to be uniquely human.
In a new development that has sent shockwaves through the AI community, OpenAI announced that its latest experimental reasoning model has achieved gold medal performance at the 2025 International Mathematical Olympiad (
IMO). This isn't just another incremental improvement in AI capabilities.
The Competition That Defines Mathematical Excellence
The International Mathematical Olympiad isn't your typical math test. Since 1959, this annual competition has brought together the brightest high school mathematicians from around the world to tackle six problems that would challenge even seasoned university professors. These aren't questions you can solve by plugging numbers into formulas. They demand deep insight, creative problem-solving approaches, and the ability to construct rigorous mathematical proofs that can span multiple pages.
To put this in perspective, OpenAI's model solved the first five of the six official problems and earned 35 out of a possible 42 points, enough to secure gold medal status. The model worked under the exact same conditions as human contestants: two 4.5-hour exam sessions, no external tools or internet access, and the requirement to write complete natural language proofs for each solution.
From Minutes to Hours: The Evolution of AI Mathematical Reasoning
What makes this achievement particularly remarkable is the progression of AI mathematical reasoning over time. OpenAI researcher Alexander Wei outlined this evolution in terms of reasoning time horizons. Early benchmarks like GSM8K, which contains grade school word problems, typically require about 0.1 minutes for top human performers to solve. The MATH benchmark steps this up to roughly 1 minute, while AIME problems demand around 10 minutes of sustained thinking.
IMO problems represent an entirely different category, requiring approximately 100 minutes of deep, creative mathematical reasoning. This isn't just about computational speed or pattern recognition. These problems demand the kind of mathematical intuition and creative insight that has traditionally separated the most gifted human mathematicians from everyone else.
Beyond Simple Verification: The Challenge of Complex Proofs
Previous AI mathematical achievements often relied on problems with clear-cut, easily verifiable answers. IMO problems break this mold entirely. The solutions are multi-page proofs that require human experts to evaluate their correctness and mathematical rigor. As Wei noted, "we've obtained a model that can craft intricate, watertight arguments at the level of human mathematicians."
This represents a fundamental shift in AI capabilities. The model isn't just finding correct answers; it's constructing sophisticated mathematical arguments that demonstrate genuine understanding of complex mathematical concepts and relationships. Three former IMO medalists independently graded each of the model's submitted proofs, requiring unanimous consensus before finalizing scores.
The Technology Behind the Breakthrough
OpenAI's approach to achieving this milestone breaks new ground in several key areas. Rather than developing narrow, task-specific methods for mathematical problem-solving, the company focused on advances in general-purpose reinforcement learning and test-time compute scaling. This means the underlying technology could potentially be applied to other complex reasoning tasks beyond mathematics.
The model represents what OpenAI calls an "experimental reasoning LLM," suggesting it incorporates significant advances in how AI systems approach multi-step reasoning problems. While the company hasn't released detailed technical specifications, the achievement suggests substantial improvements in how AI models can maintain coherent reasoning over extended periods and construct complex logical arguments.
Before anyone gets too excited about testing their own mathematical prowess against this AI champion, OpenAI made it clear that this technology won't be available to the public anytime soon. The company explicitly stated that while GPT-5 is coming soon, the IMO gold medal model is purely experimental research and won't be released with this level of mathematical capability for several months.
This measured approach reflects the significant gap between research breakthroughs and practical deployment. The model that achieved IMO gold likely requires substantial computational resources and may have quirks or limitations that make it unsuitable for general use. As Wei noted somewhat apologetically, the model has a "distinct style" that suggests it's very much a work in progress.
Racing Against Predictions: When AI Exceeds Expectations
Perhaps the most striking aspect of this breakthrough is how dramatically it exceeded expert predictions. In 2021, Wei's PhD advisor asked him to forecast AI mathematical progress by July 2025. His prediction? A 30% success rate on the MATH benchmark, which he considered optimistic compared to other forecasters. Instead, we now have an AI system achieving gold medal performance at the IMO, a far more challenging benchmark.
This rapid acceleration in AI capabilities highlights the difficulty of predicting technological progress, even for experts working directly in the field. While AI models now achieve near-perfect scores on traditional benchmarks like GSM-8k and MATH, they solve less than 2% of FrontierMath problems, suggesting there are still significant mathematical challenges ahead.
Competition in the AI Mathematical Arena
OpenAI's achievement comes amid intense competition in AI mathematical reasoning. Back in July 2024, Google DeepMind announced
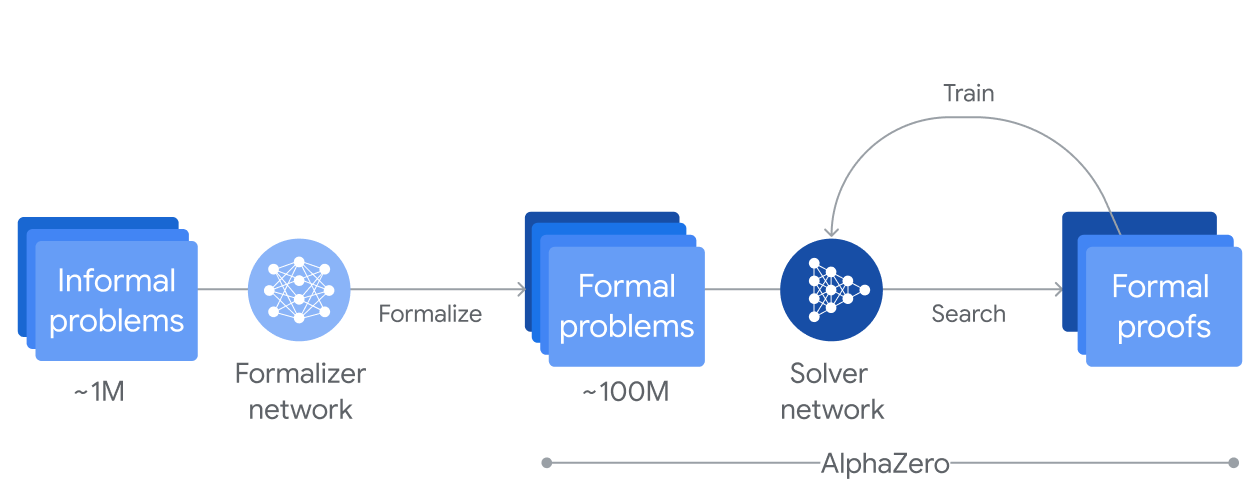
AlphaProof and
AlphaGeometry 2, systems that solved four out of six problems from this year's IMO, achieving silver medal standard. This rapid progress from multiple research teams suggests that mathematical reasoning has become a key battleground for demonstrating advanced AI capabilities.
The competition extends beyond just solving problems to developing different approaches. While some systems focus on formal mathematical reasoning using proof assistants, OpenAI's model works with natural language proofs, more closely mimicking how human mathematicians communicate their solutions.
What This Means for the Future of AI
The implications of this breakthrough extend far beyond mathematics competitions. The ability to engage in sustained, creative reasoning over extended time periods represents a crucial step toward more general artificial intelligence. Mathematical problem-solving requires many of the cognitive abilities that humans use in other complex domains: pattern recognition, analogical reasoning, creative insight, and the ability to construct and verify complex logical arguments.
Despite this remarkable achievement, OpenAI was careful to acknowledge the human element that makes the IMO special. The competition continues to showcase some of the brightest young mathematical minds from around the world, and many former IMO participants now work at leading AI companies, including OpenAI itself.
The model's success doesn't diminish the remarkable achievement of human IMO contestants. Instead, it represents a new kind of collaboration between human mathematical insight and artificial intelligence capabilities. The problems were created by humans, the evaluation standards were set by humans, and the significance of the achievement is ultimately measured by human values and goals.
OpenAI Proofs on Github:
https://github.com/aw31/openai-imo-2025-proofs/Recent Posts