geeky NEWS: Navigating the New Age of Cutting-Edge Technology in AI, Robotics, Space, and the latest tech Gadgets
As a passionate tech blogger and vlogger, I specialize in four exciting areas: AI, robotics, space, and the latest gadgets. Drawing on my extensive experience working at tech giants like Google and Qualcomm, I bring a unique perspective to my coverage. My portfolio combines critical analysis and infectious enthusiasm to keep tech enthusiasts informed and excited about the future of technology innovation.
Google Gemma 3n Turn Every Smartphone Into an AI Powerhouse Without Cloud
AI Summary
Google has unveiled Gemma 3n, an AI model designed to run entirely on mobile devices, offering performance comparable to larger cloud-based systems. This innovation addresses the memory limitations of mobile AI through "Per-Layer Embeddings" (PLE), allowing the 5-billion parameter E2B model to operate with an effective memory footprint of just 1.91 billion parameters, requiring only about 2GB of RAM. Additionally, the "MatFormer architecture" enables a nesting doll-like structure, where the larger E4B model contains a complete E2B model, offering dynamic scalability.
May 27 2025 07:45
Google just unveiled Gemma 3n, an AI model specifically engineered to run entirely on mobile devices while delivering performance that rivals much larger, cloud-based systems. This isn't just another incremental improvement in mobile AI. It's a fundamental shift in how artificial intelligence will work on the devices we carry every day.
The timing couldn't be more significant. As AI capabilities have exploded over the past few years, most of the impressive demos you've seen require powerful servers in distant data centers. Want to have a conversation with ChatGPT? Your phone sends your message to the cloud. Need Google's Bard to analyze an image? Off to the servers it goes. Gemma 3n changes that equation entirely.
The Memory Problem That Stumped Everyone
To understand why Gemma 3n matters, you need to grasp the fundamental challenge that has plagued mobile AI for years: memory. Modern AI models are memory hungry beasts. Even relatively small language models typically require several gigabytes of RAM just to load, let alone run efficiently. Your iPhone or Android device, meanwhile, needs to juggle dozens of apps, the operating system, photos, and everything else you do on your phone.
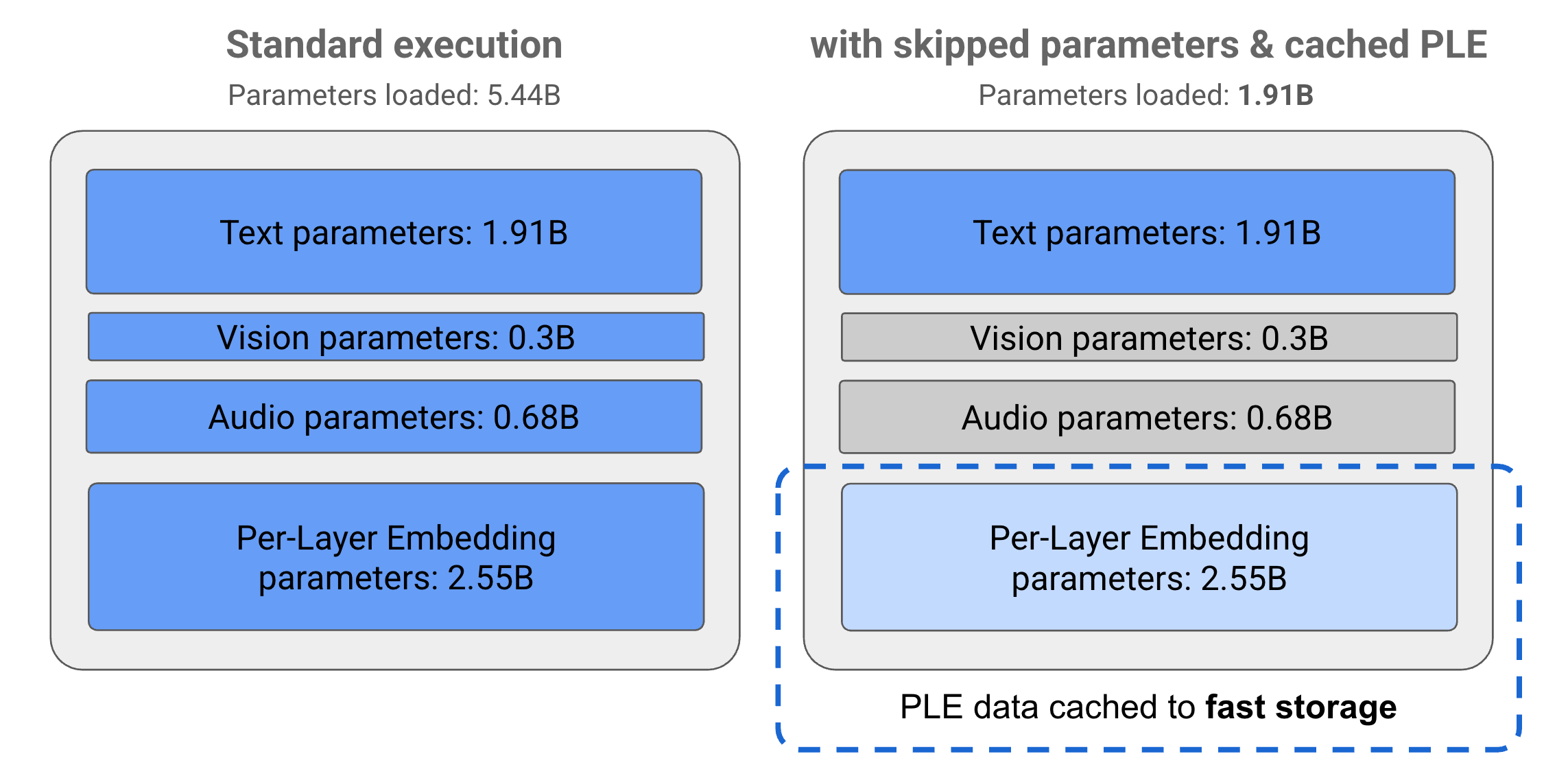
Google's solution is genuinely clever. Instead of just making a smaller AI model that would inevitably be less capable, their engineers developed something called Per-Layer Embeddings, or PLE. Think of it like having a really smart filing system for your brain. Instead of keeping all your knowledge active in your working memory at once, you file away the less immediately relevant information and pull it out only when needed.
The result is striking: Gemma 3n's E2B model technically contains over 5 billion parameters, but through this PLE caching system, it operates with an effective memory footprint of just 1.91 billion parameters. That translates to running comfortably in about 2GB of RAM, a reasonable ask for most modern smartphones.
MatFormer Architecture
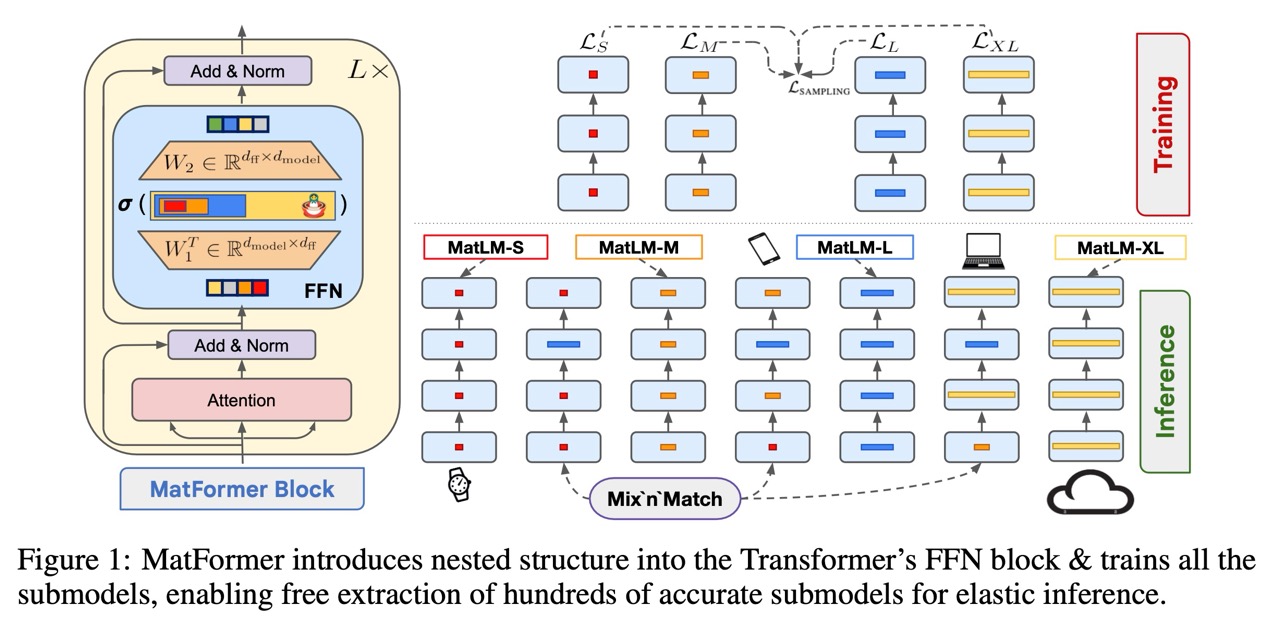
But Google didn't stop with clever memory management. They also developed what they call MatFormer architecture. The larger Gemma 3n E4B model literally contains a complete, smaller E2B model inside it. This means developers can dynamically choose which version to run based on the task at hand and available device resources.
Need to quickly transcribe a voice memo? Fire up the smaller, faster model. Working on a complex document analysis? Activate the full model. The genius is that you don't need to store and manage separate models for different use cases. It's all contained in one package that can adapt on the fly.
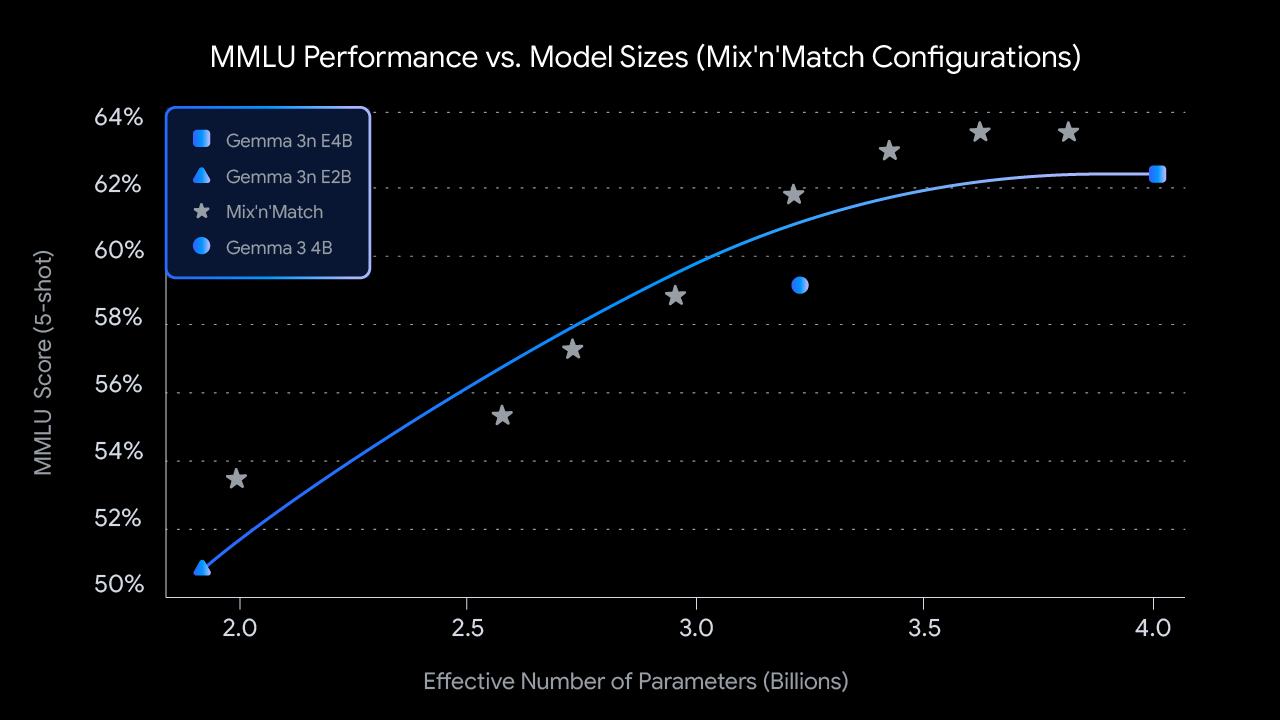
This flexibility extends even further through what Google calls "mix and match" capability. Developers can essentially create custom model sizes between the 2B and 4B versions, fine-tuning the performance and efficiency tradeoff for their specific applications.
Beyond Text: The Multimoda Advantage
Perhaps most impressively, Gemma 3n isn't limited to text processing. The model can simultaneously handle audio, images, video, and text inputs in what researchers call "interleaved" processing. In plain English, this means you could show your phone a video while asking a question about it out loud, and the AI would understand both the visual content and your spoken query together.
The audio capabilities alone represent a significant leap forward. Gemma 3n can perform high-quality speech recognition and translation entirely on-device. Imagine having a real-time translator in your pocket that works even when you're deep in a foreign country with no cell service.
The model also supports over 140 languages and can handle 32,000 tokens of context, meaning it can work with fairly lengthy documents or conversations while maintaining coherence throughout.
It is available now through Google AI Studio for cloud-based experimentation and Google AI Edge for on-device development. Like other Gemma models, it comes with open weights and licensing that allows commercial use.
All of this on-device processing creates a privacy advantage that's hard to overstate. When your AI assistant runs locally, your conversations, photos, and documents never leave your device. There's no corporate server analyzing your personal information, no risk of data breaches exposing your private interactions, and no dependency on internet connectivity for AI features to work.
This represents a fundamental philosophical shift in how AI services are delivered. Instead of the current model where tech companies provide "free" AI services in exchange for your data, Gemma 3n enables truly private AI that runs on hardware you own and control.
Hardware Partners Make It Real
Google didn't develop Gemma 3n in isolation. The company worked closely with major mobile chip manufacturers including Qualcomm, MediaTek, and Samsung System LSI to optimize the model for real-world mobile hardware. This collaboration suggests that Gemma 3n isn't just a research project but a technology designed for widespread deployment across Android devices.
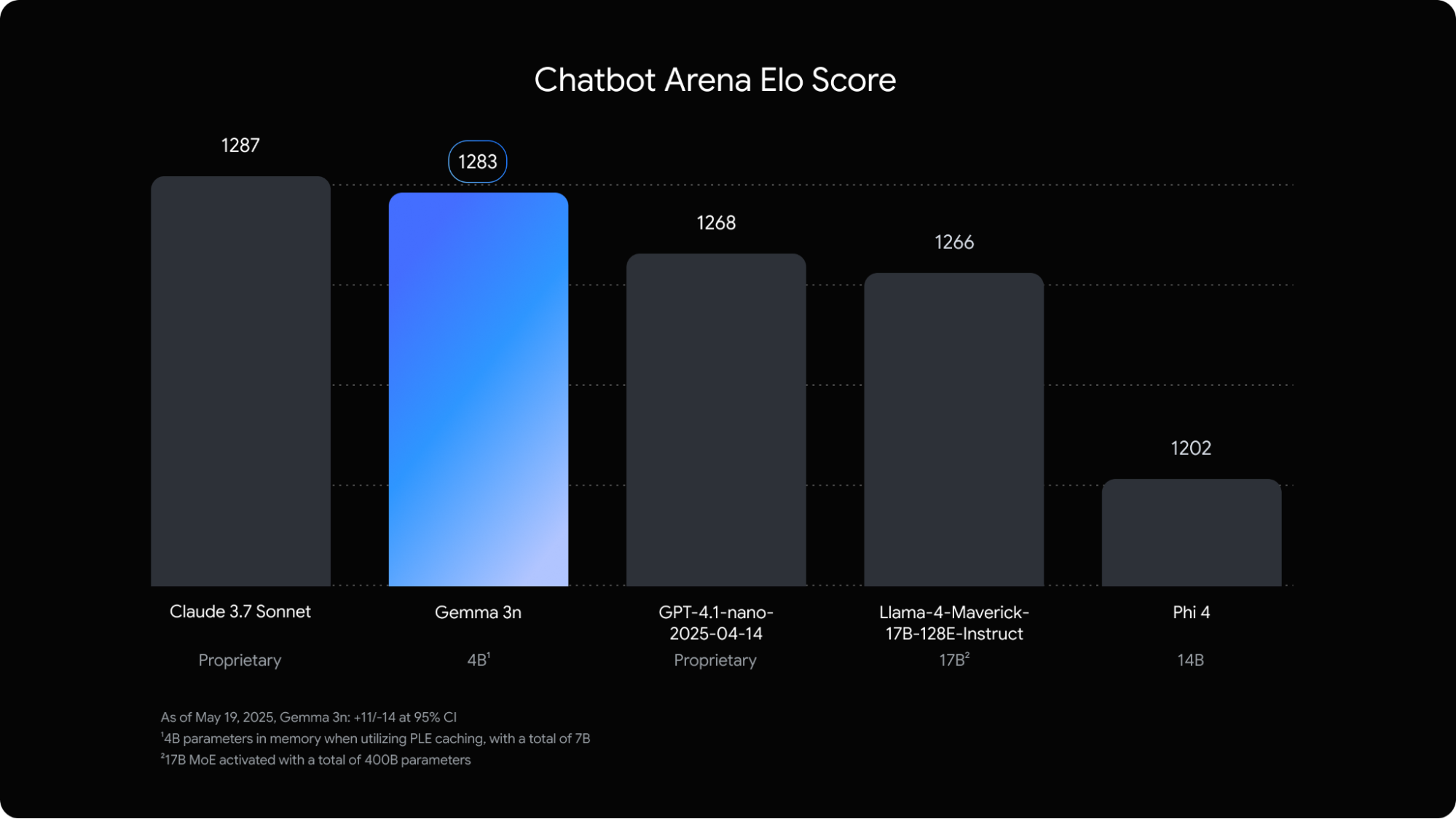
The performance improvements are already measurable. Google reports that Gemma 3n responds approximately 1.5 times faster on mobile devices compared to the previous Gemma 3 4B model, while delivering significantly better quality results.
Real-World Performance: The Good, Bad, and Surprising
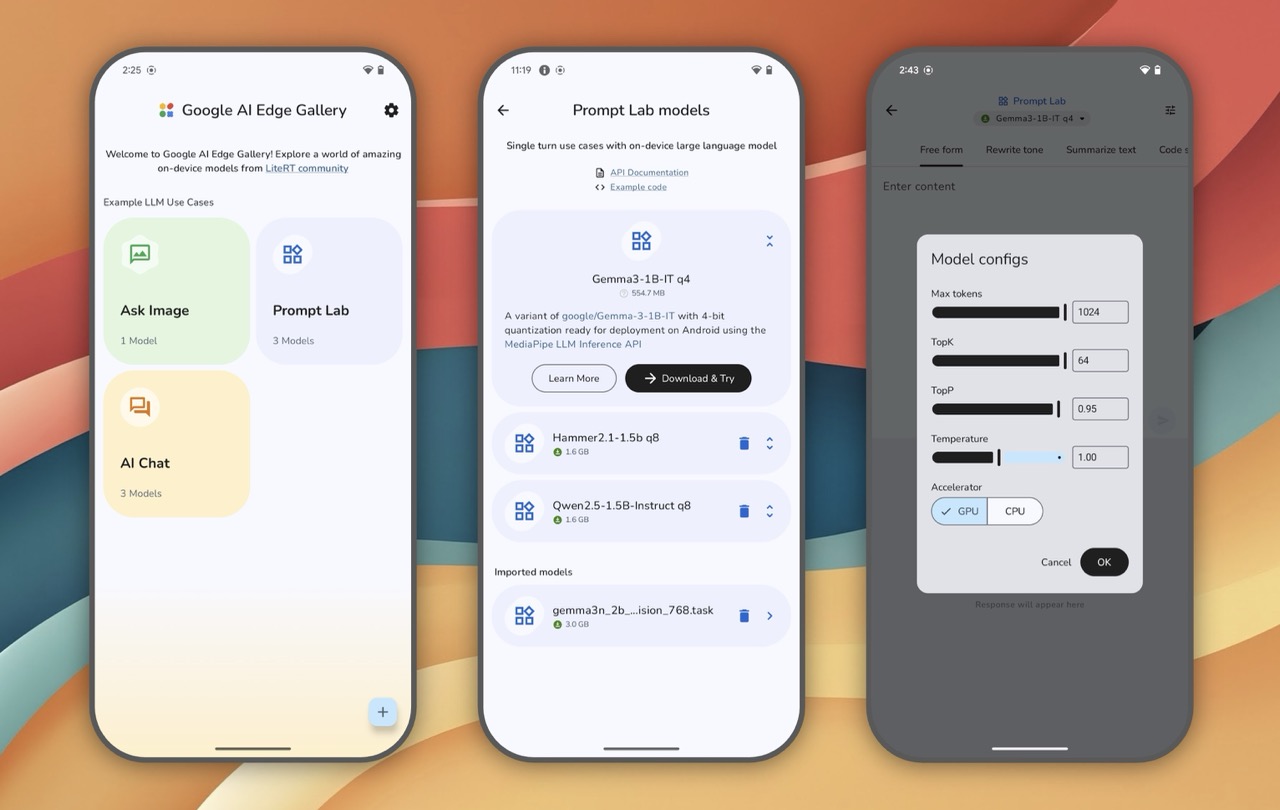
Early adopters have put Gemma 3n through its paces across a variety of Android devices, and the results paint a nuanced picture. Using the Google Edge AI apk Android app available on GitHub, users can download and test the model themselves, providing a rare glimpse into how cutting-edge AI performs in everyday conditions. The performance varies dramatically based on your device's age and specifications. Here's what Harker News users are experiencing:
Pixel 4a (2020): 0.33 tokens per second, taking over 10 minutes for a single image description
Pixel Fold: 3.1-5.8 tokens per second, with GPU acceleration providing significant speedup
Pixel 6 Pro (2021): 4.4-6+ tokens per second, surprisingly good for a 4-year-old device
Galaxy Z Fold 4 (2022): 7+ tokens per second, among the best performance reported
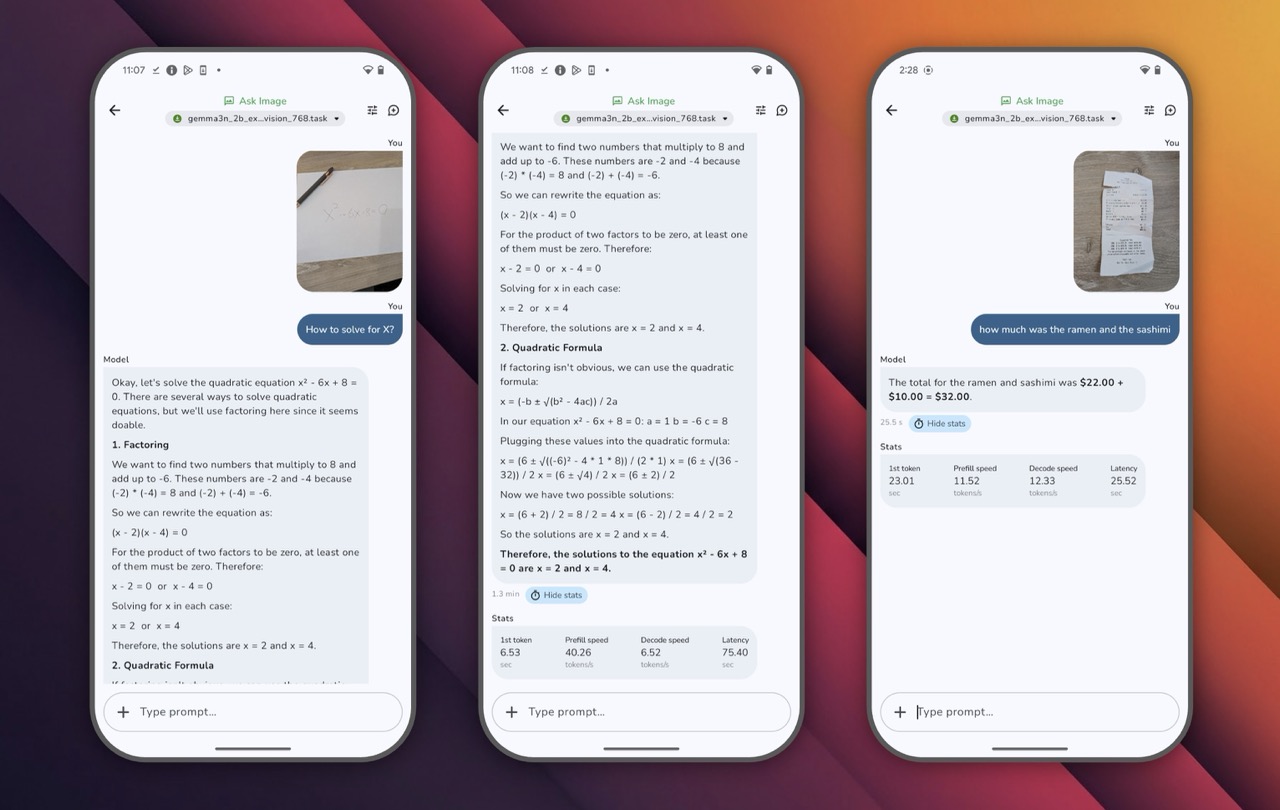
Testing the iOS app on my iPhone 15 Pro Max with Hugging Face's Gemma 3n 4B model yielded impressive results: a 9.369-second model load time and a solid 7.69 tokens per second throughput. When I tasked the model with analyzing a photo from my library, performance shifted as expected for multimodal processing—taking 22.911 seconds to generate a comprehensive image summary at 5.28 tokens per second. For on-device inference on mobile hardware, these performance metrics demonstrate the viability of running larger language models locally on flagship iOS devices, even when handling complex vision tasks.
One user testing image recognition was impressed by the model's ability to interpret a blurry, poorly-angled photo of a monitor displaying various statistics. Despite the challenging conditions, Gemma 3n correctly identified weather information, temperature readings, CO2 levels, and power consumption data, though it did make some reading errors with small text.
This performance gap has practical implications. While newer devices can handle conversational AI reasonably well, older phones struggle with even basic tasks. A simple image description that takes 12 seconds on a recent flagship might take 10 minutes on a phone that's just a few years old.
Perhaps the most striking finding from these tests is how dramatically performance scales with device age. The difference between a 2020 Pixel 4a and a 2022 Galaxy Z Fold 4 represents "a full order of magnitude difference in token generation rate," as one user noted. This stark contrast led to the observation: "Who said Moore's Law is dead?"
What This Means for Developers
For developers, Gemma 3n opens up entirely new categories of mobile applications. Consider these possibilities:
Real-time video analysis apps that can understand and respond to what your camera sees
Voice-driven interfaces that work reliably offline
Document processing tools that can analyze, summarize, and answer questions about files stored locally without cloud uploads
Language learning apps with sophisticated conversation practice
Accessibility tools that can describe visual content in real-time
Offline language translation with visual context
One user suggested that the future might involve local models handling pattern matching and planning tasks, while connecting to more powerful cloud-based AI only for computationally intensive work. This hybrid approach could offer the best of both worlds: privacy and speed for routine tasks, with access to advanced capabilities when needed.
The Technical Challenges
Despite the impressive achievements, Gemma 3n faces several technical hurdles. GPU acceleration, while faster than CPU processing, comes with trade-offs. As one developer noted, "you really notice that the model is dumber on GPU, because OpenGL doesn't take accuracy that seriously." Users also reported various bugs and inconsistencies:
Some GPU acceleration attempts resulted in infinite loops of nonsensical output
The model sometimes struggles with following complex instructions
Performance can be inconsistent even on the same device
The app requires initial internet connectivity to download models and agree to terms
Interestingly, while the model theoretically supports smartphone Neural Processing Units (NPUs) designed specifically for AI tasks, current implementations seem limited to CPU and GPU acceleration. This raises questions about how well-optimized the current release is for mobile hardware.
What This Means for the Future
Gemma 3n represents a significant milestone in democratizing AI access. For the first time, smartphone users can run models that approach the capabilities of premium cloud-based services, entirely offline and for free. This has profound implications for privacy, accessibility, and global AI access.
However, the current state reveals we're still in the early stages of mobile AI. The dramatic performance differences between devices suggest that truly accessible on-device AI will require either more efficient models or more powerful mobile hardware. The good news is that both are rapidly improving.
For developers and tech enthusiasts, Gemma 3n offers a glimpse into a future where AI becomes as ubiquitous and accessible as a calculator. For everyday users, it's a reminder that cutting-edge technology often comes with practical limitations that take time to resolve.