AI Summary
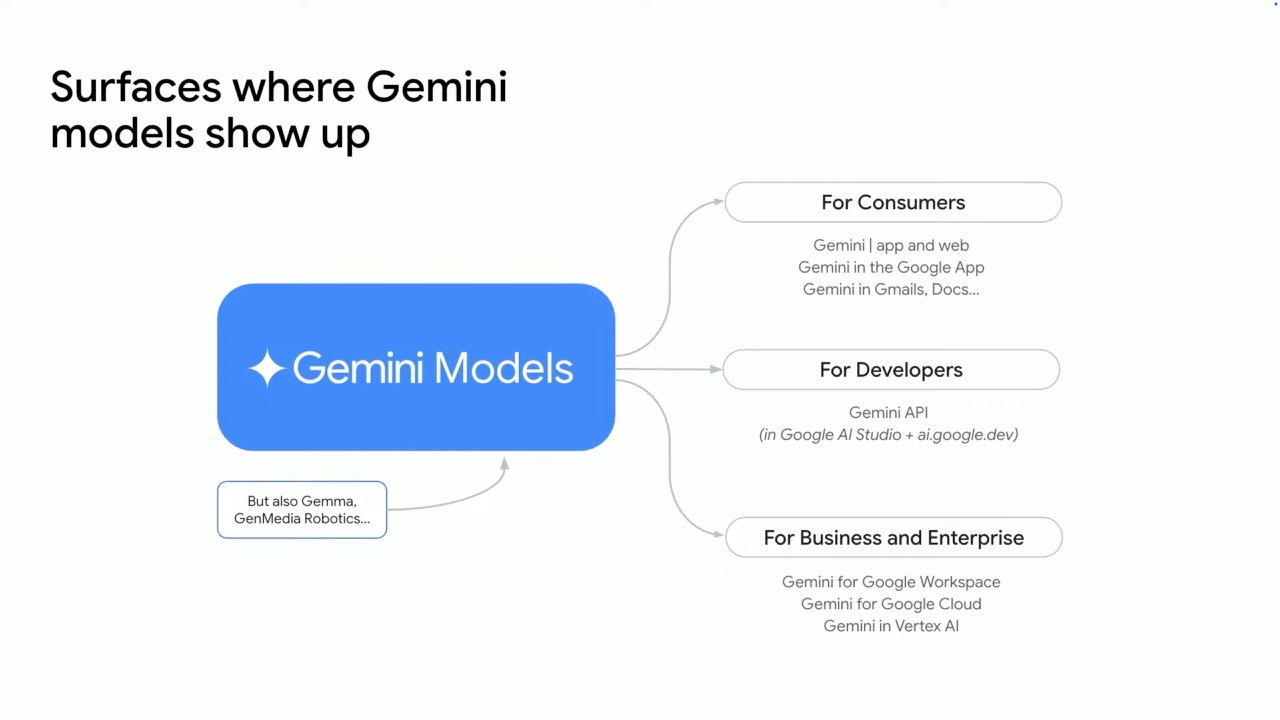
At Google I/O, Google unveiled significant advancements in its AI offerings, centered around an expanded Gemini model universe and enhanced API capabilities. New Gemini models like 2.5 Pro, Flash, Flash-Lite, Nano, and Embedding provide diverse solutions for complex tasks, high-volume operations, and on-device applications, excelling in performance benchmarks. The Gemini API offers broad access with new audio generation capabilities, multimodal understanding for video and image analysis, improved context handling, and real-time interaction features via the Gemini Live API.
Google's recent announcements at I/O showcase significant advancements in their AI offerings, with new Gemini models and API capabilities that expand what developers can build. As the tech landscape evolves, these tools provide sophisticated multimodal understanding with improved performance, broader language support, and enhanced developer experiences.
The Gemini Model Universe
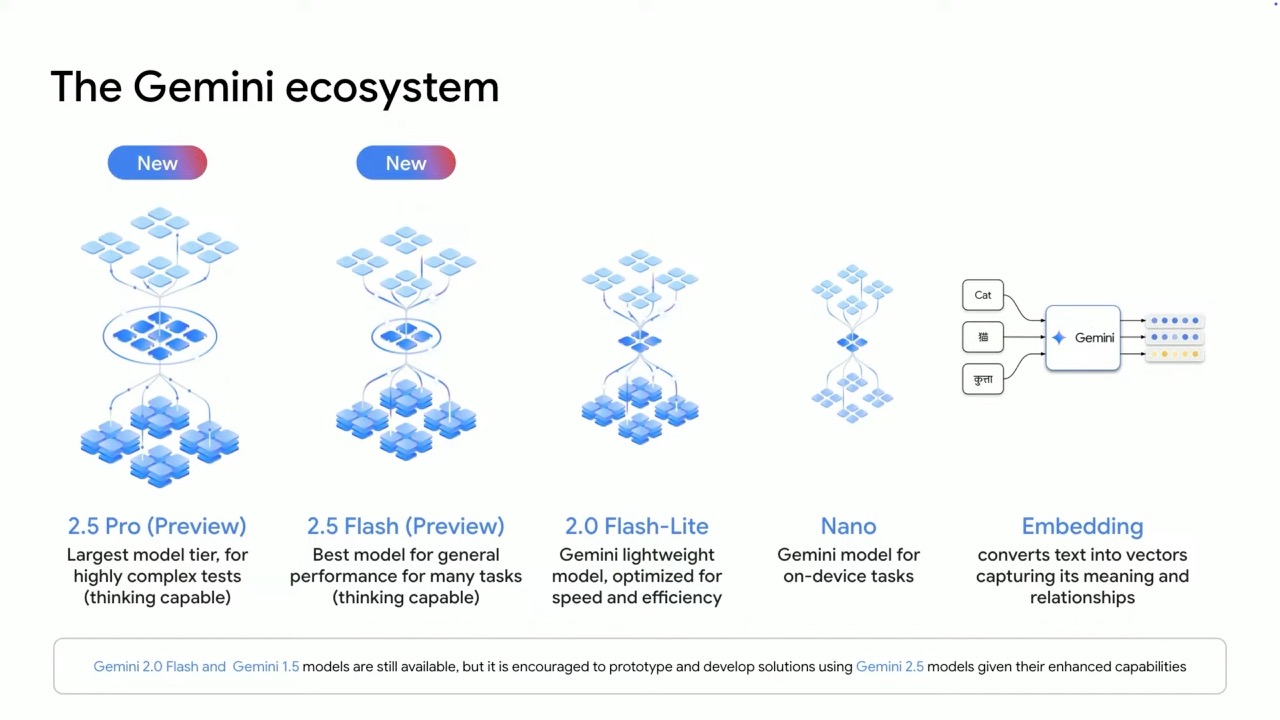
Google DeepMind has expanded its Gemini family with several new models designed to handle different use cases and computing environments:
- Gemini 2.5 Pro: The flagship model suitable for highly complex tasks requiring deep reasoning, with coding being a standout use case
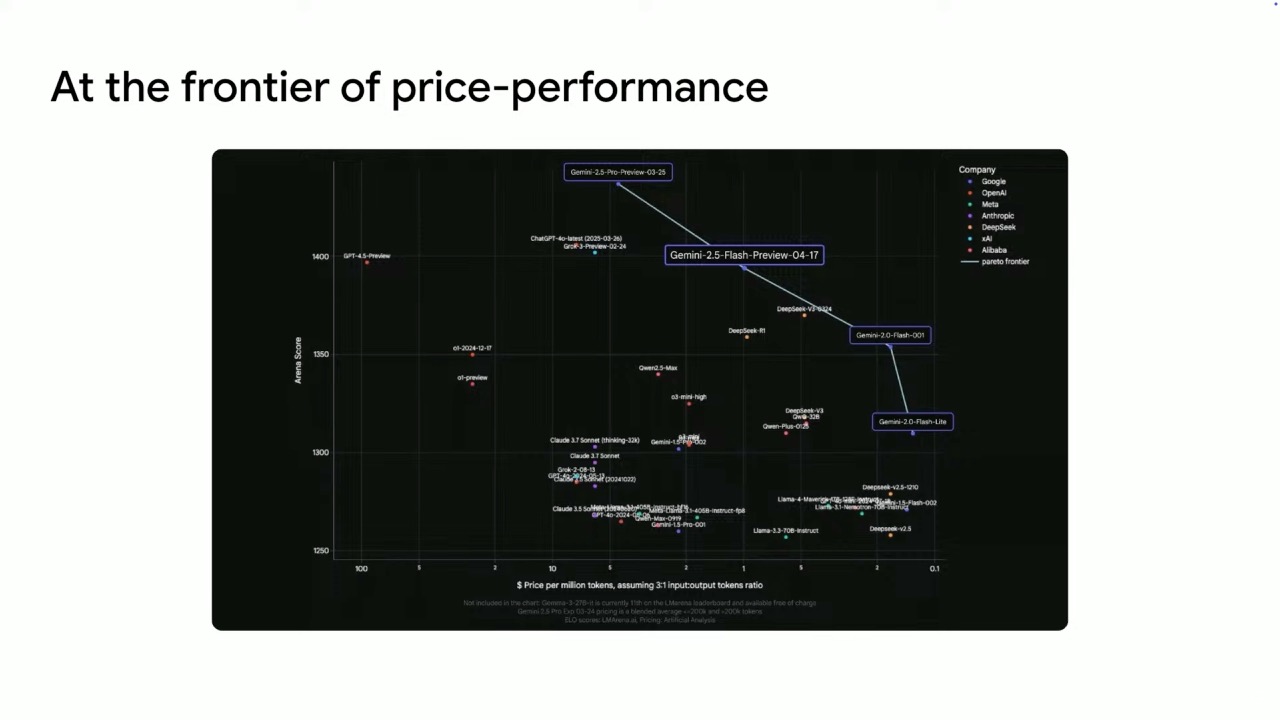
- Gemini 2.5 Flash: A model with one of the best price-performance ratios in the market
- Gemini 2.0 Flash-Lite: A small, fast, affordable model for high-volume tasks like summarization
- Gemini Nano: Designed for on-device applications, particularly for Android devices using AICore
- Gemini Embedding: Specialized for semantic ranking and organization at scale
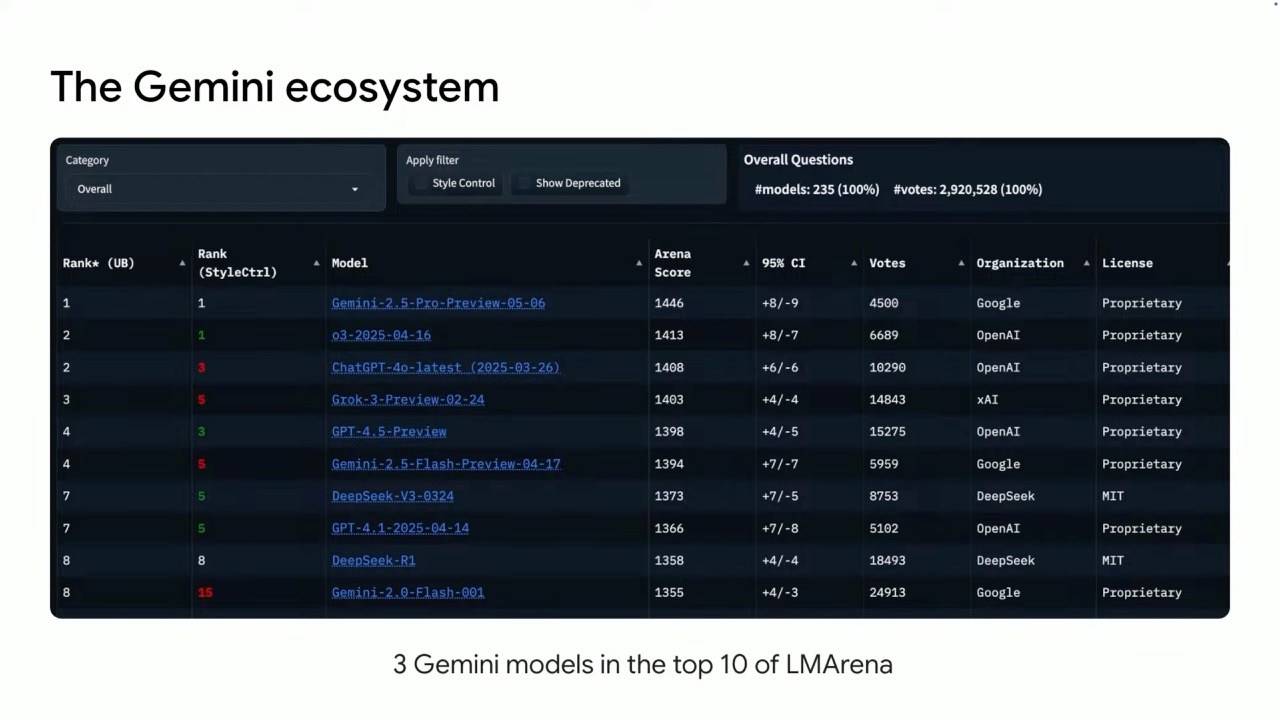
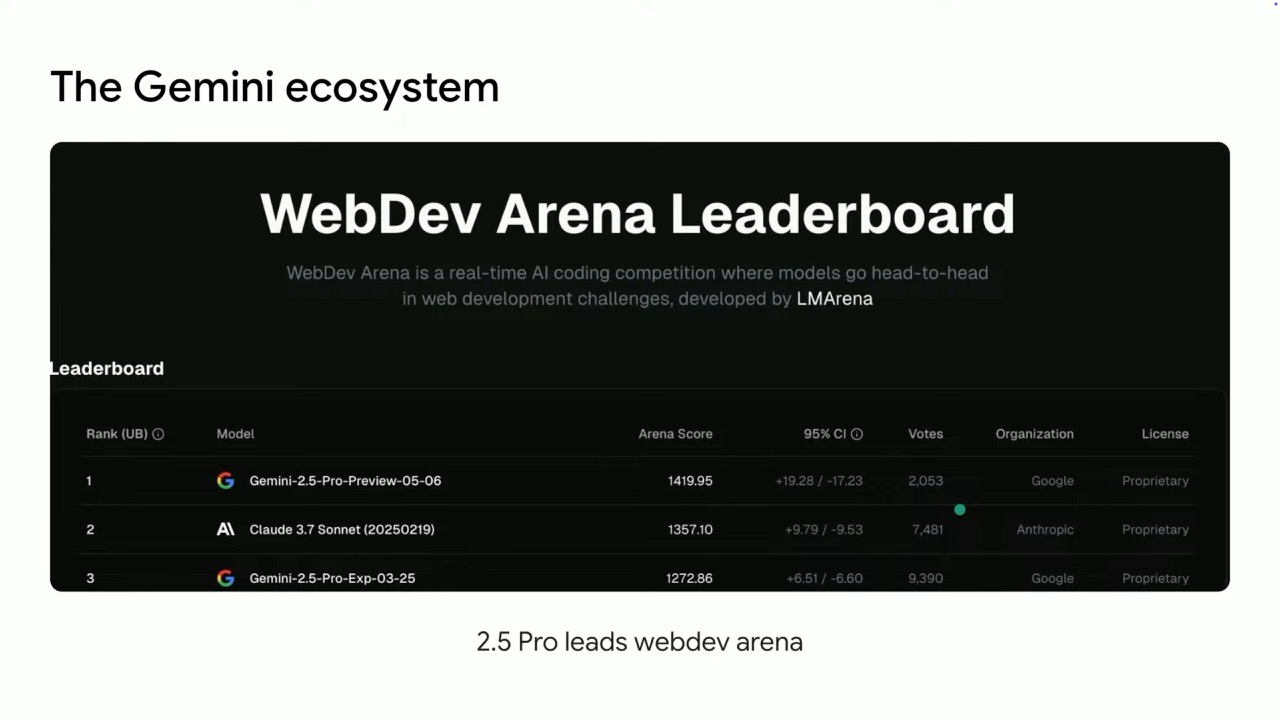
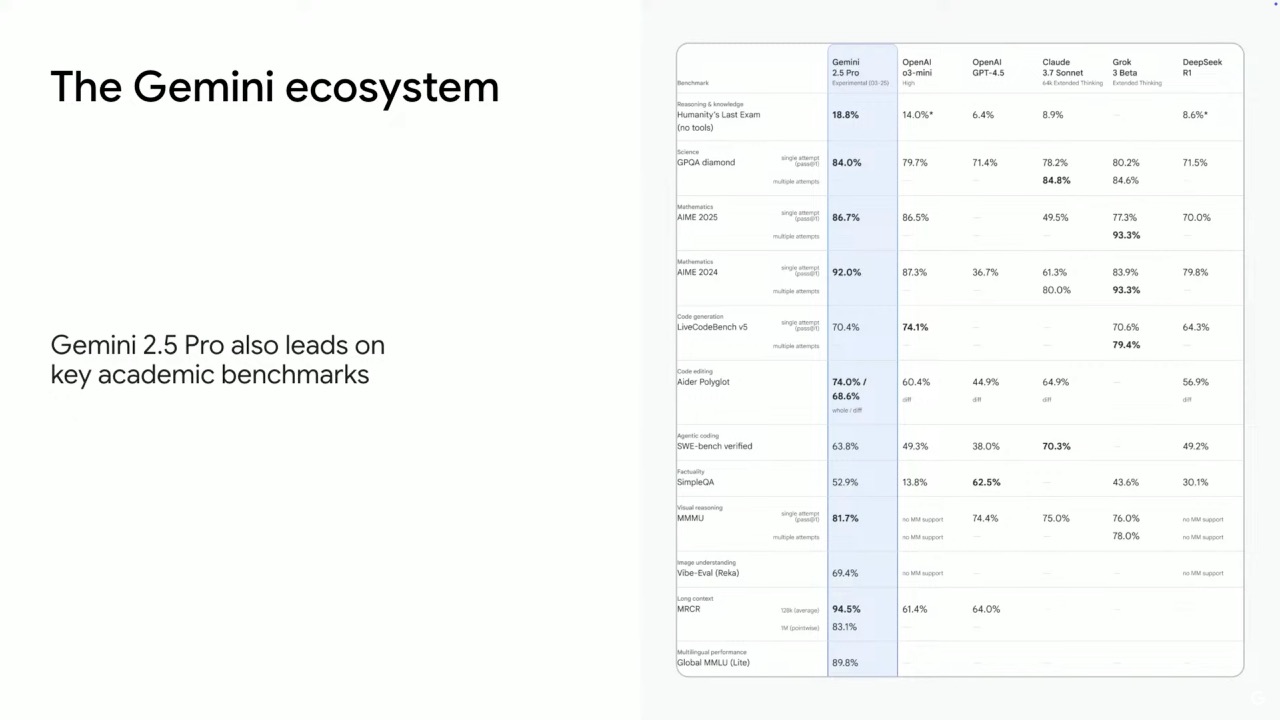
These models are leading performers across key standard benchmarks, with three Gemini models currently in the top 10 in the LM Arena. Notably, Gemini 2.5 Pro holds the #1 position for both general performance and in the WebDev arena for app creation and coding.
New Audio Capabilities: Advancing Voice Interactions
One of the most requested features has been high-quality audio generation, which Google has addressed with two major additions:
- Gemini TTS Model: A new text-to-speech model that creates high-quality audio with customizable emotions, multiple voices, different languages, and the ability to create multi-speaker interactions.
- Native Audio Output Models: Google's first release of an audio-to-audio architecture available through the Gemini Live API with two variants: Standard native audio dialogue model with more natural voices and Thinking-enabled version for more complex use cases
These models offer better contextual understanding of human speech and can seamlessly transition between different languages, making them ideal for applications requiring natural voice interactions.
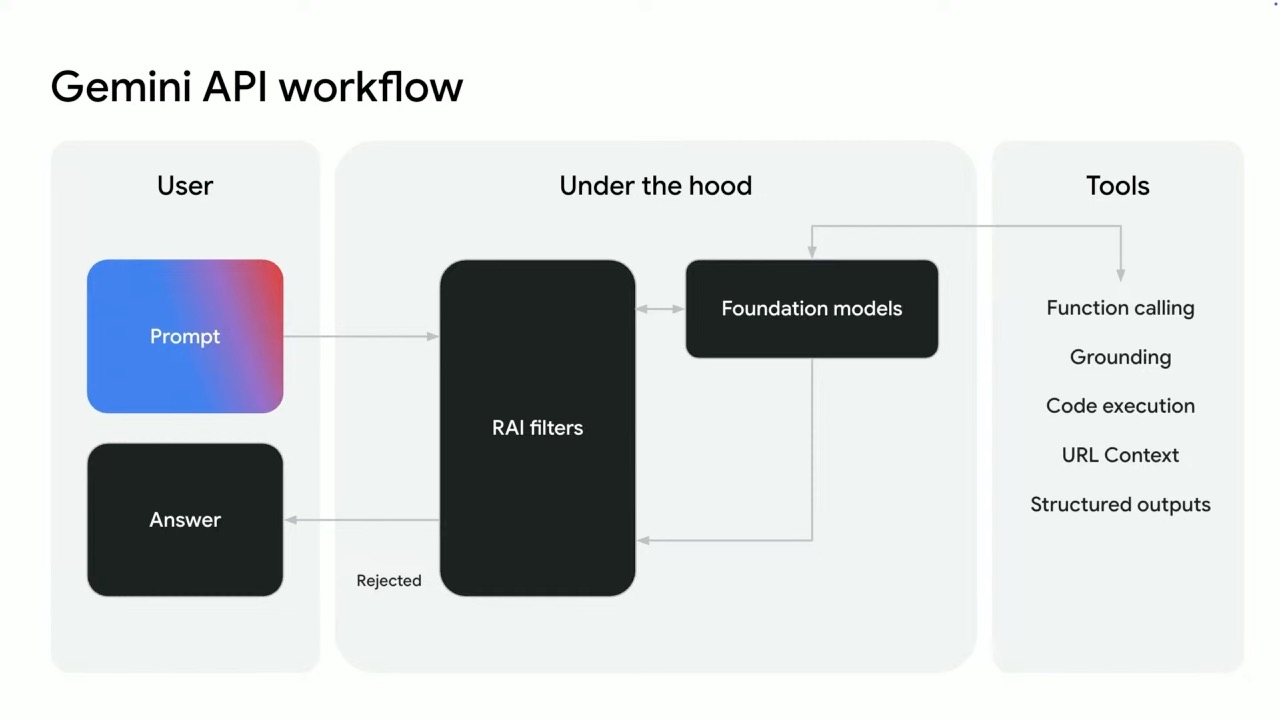
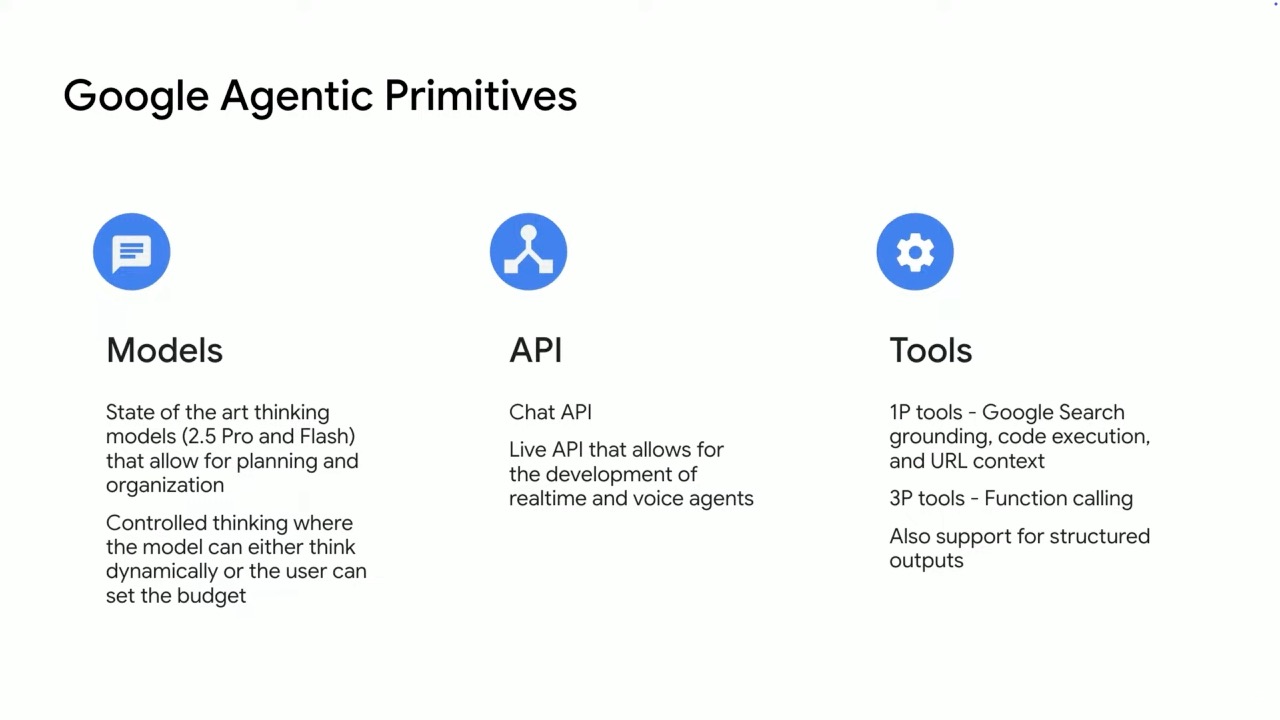
The Gemini API: Low-Barrier Entry to AI Development
The Gemini API provides developers with programmatic access to all Gemini models with a generous free tier for experimentation. Google has developed SDKs for Python, JavaScript, and Go, with integration into popular developer tools like Firebase Studio and Google Colab. Key components of the Gemini API include:
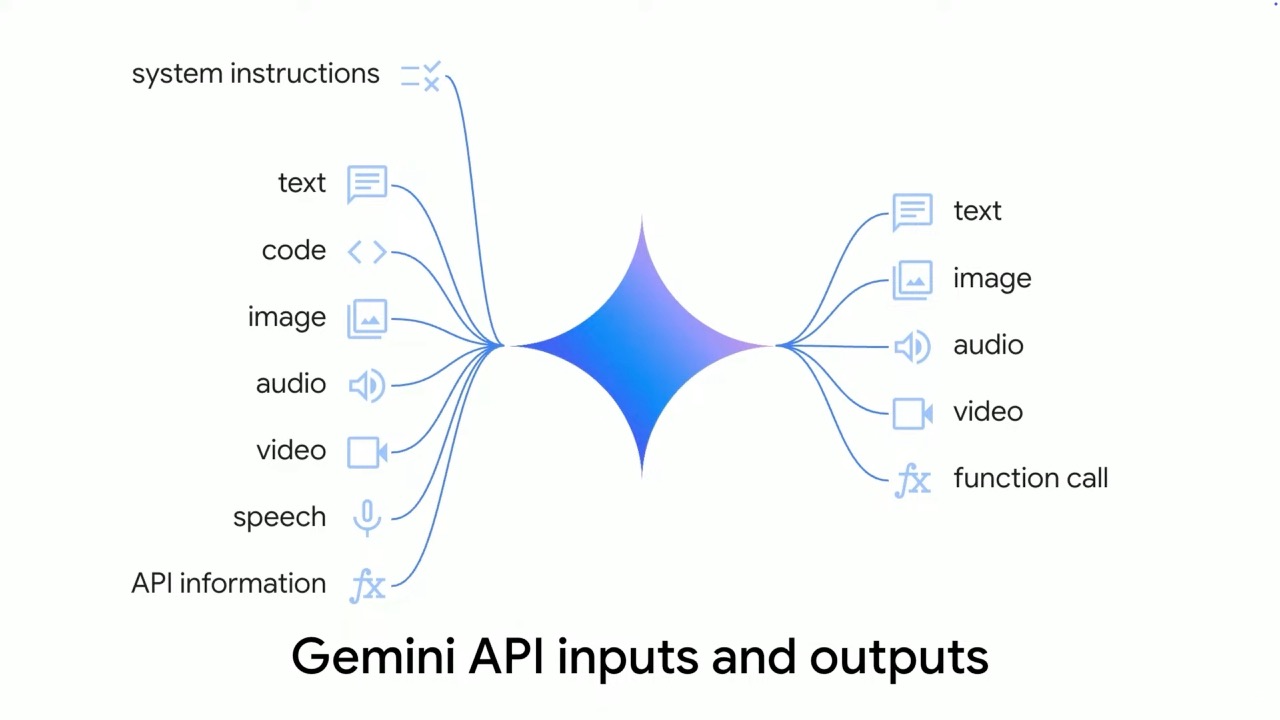
- Input handling for text, images, video, and audio
- Tool integration with Google Search, URL context, and code execution
- Function calling capabilities
- Structured output functionality for JSON schema
Configurable safety and copyright filters
Multimodal Understanding: Beyond Simple Text Prompts
Gemini models excel at understanding multiple forms of information simultaneously:
- Video analysis with three resolution settings (processing up to 6 hours of video at the lowest setting)
- Support for dynamic frame rate per second
- Video clipping capabilities
- Image segmentation with bounding boxes
The models can understand semantic connections between information in different formats, such as connecting data in PDF files with spreadsheets and videos without requiring extensive developer work.
Context Handling and Optimization
Gemini offers some of the largest context windows available, allowing developers to process extensive amounts of information in a single prompt. To manage the increased token costs associated with long contexts, the API now supports:
- Explicit context caching: Developers can manually specify contexts to cache with a 75% discount on pricing
- Implicit context caching: The system automatically caches frequently used contexts and passes savings to developers
The Gemini Live API: Real-Time Interactions
For applications requiring interactive, real-time experiences, the Gemini Live API offers two architecture options:
- Cascaded architecture with native audio input and text-to-speech output
- Audio-to-audio architecture with native audio input and output
Enhanced features:
- Tool chaining support (search, code execution, URL context, function calling)
- Configurable voice activity detection
- Session management for extended interactions
- Proactive audio capabilities where the AI decides when to respond
- Affective dialogue that picks up on user tone and sentiment
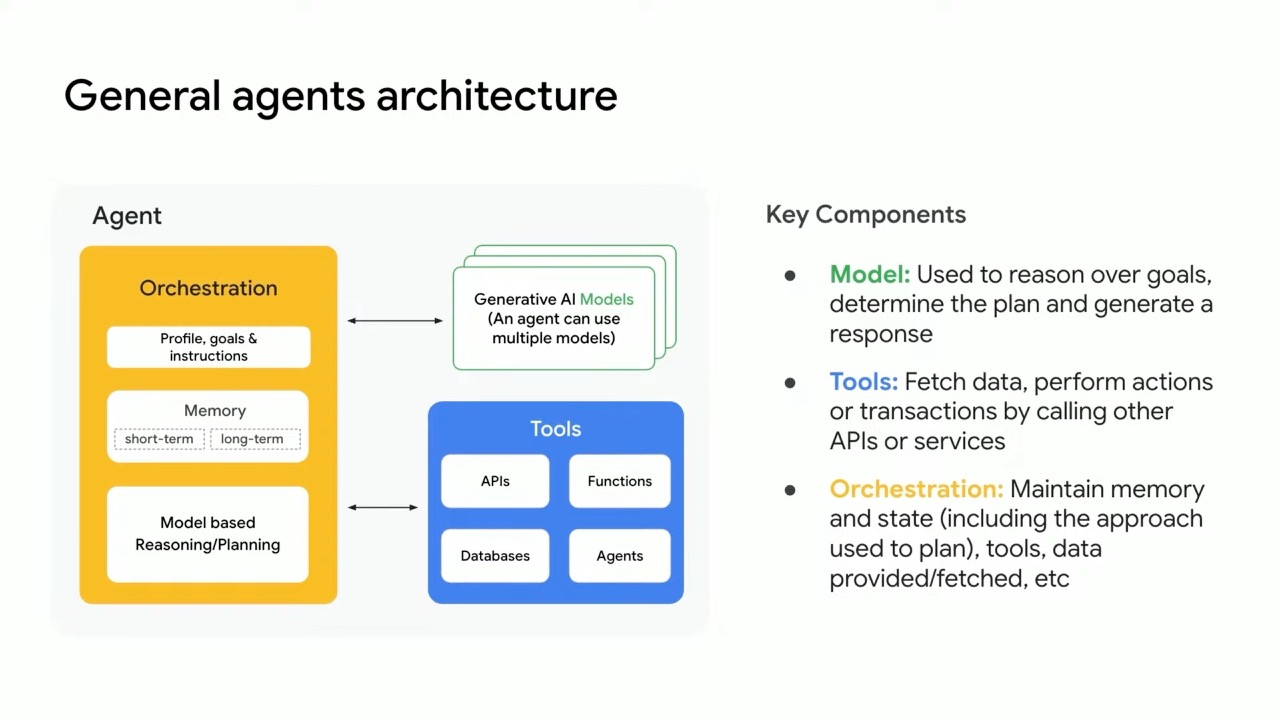
Building Agentic Applications with Gemini
The Gemini 2.5 models are particularly well-suited for creating autonomous agents due to their strong reasoning capabilities. When building agents, developers typically work with three main components:
- Orchestration Layer: Defines the agent's behavior, goals, and profile
- Model Layer: Handles reasoning and planning (where Gemini 2.5 Pro excels)
- Tools Layer: Integrates with external tools and services
New agent-focused capabilities include:
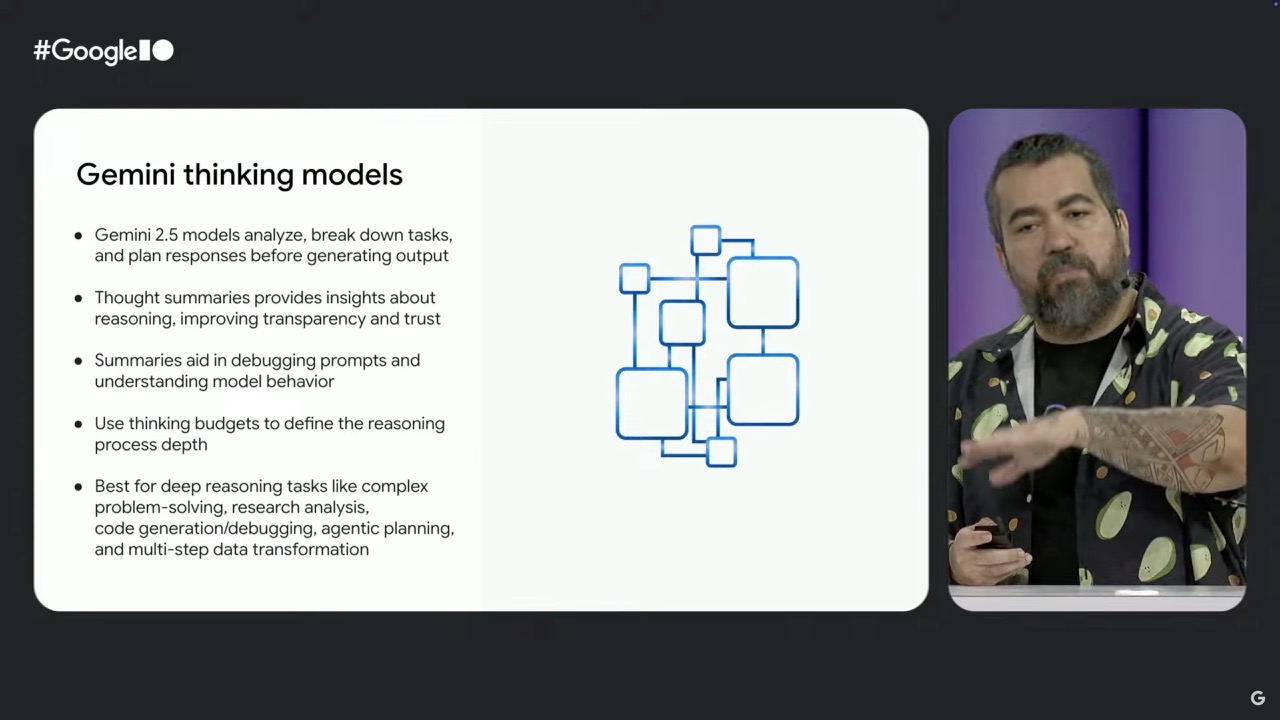
- Thinking Budget: Allows developers to calibrate reasoning cycles and control costs
- Thought Summaries: Shows the model's reasoning process in responses
- Tool Chaining: Combines multiple tools like Google Search and code execution in a single interaction
- URL Context: Extracts in-depth content from web pages for research use cases
- Asynchronous Functions: Performs background tasks while maintaining conversation
Gemma: Google's Open Family of AI Models
Beyond Gemini, Google has also expanded its Gemma family of open-source models, which are based on Gemini technology but designed to be freely available and modifiable:
- Gemma 3: Recently released with multimodal capabilities (images, video), support for 140+ languages, and expanded context windows up to 128K tokens
- Gemma 3n: Optimized for on-device use with as little as 2GB of RAM, supporting vision, text, and audio understanding
- Specialized variants: Including MedGemma for healthcare, SignGemma for sign language, and DolphinGemma for dolphin communication research
The open nature of Gemma has led to over 70,000 community-built model variants, allowing for specialized applications across many domains and languages.
Getting Started with Gemini and Gemma
For developers looking to experiment with these models:
- For Gemini: Start with AI Studio (ai.google.dev) to test prompts before implementing them in production
- For Gemma : Use tools like Ollama, Keras, or Gemma Python to run models locally
- For deployment: Export code from AI Studio or deploy directly to Google Cloud Run
The Path Forward for AI Development
As these models continue to evolve, Google encourages developers to focus on:
- Having clear objectives for AI applications
- Iterating frequently during development
- Using the models' own capabilities to assist with coding
- Prioritizing user experience in the final product
With extensive documentation, sample code in the Gemini cookbook GitHub repository, and multiple paths to implementation, these tools offer both flexibility and power for the next generation of AI applications.
Google AI Studio:
goo.gle/aisGoogle API Docs:
goo.gle/gemini-docsGoogle Gemini Cookbook on Github:
goo.gle/gemini-cookbookRecent Posts