AI Summary
Chatbot Arena, created in 2023, serves as a crucial platform for evaluating generative AI models through human preferences and pairwise comparisons, addressing the limitations of traditional static benchmarks. However, as it gained influence, the platform became susceptible to manipulation. A report titled "The Leaderboard Illusion" identifies systematic issues such as undisclosed private testing by a few providers (e.g., Meta, Google, OpenAI, Amazon) to select the best-performing models before public release.
Chatbot Arena was created in 2023 to fill a critical gap in evaluating rapidly advancing generative AI technology. Unlike academic multiple-choice evaluations, which often fail to reflect real-world open-ended use cases, Chatbot Arena allows anyone to submit a prompt and subsequently rank two anonymous responses from different models. This dynamic, user-driven framework can evolve alongside model capabilities and capture emerging real-world use cases.
However, as the saying goes, "Any observed statistical regularity will tend to collapse once pressure is placed upon it for control purposes" (Goodhart's Law). As Chatbot Arena has gained enormous influence over media, the AI industry, and academia, the over-reliance on a single leaderboard creates a risk that providers may optimize for leaderboard performance rather than genuinely advancing the technology. Here is the findings from a recent research paper "
The Leaderboard Illusion".
Private Testing and Selective Score Reporting: The Hidden Advantage
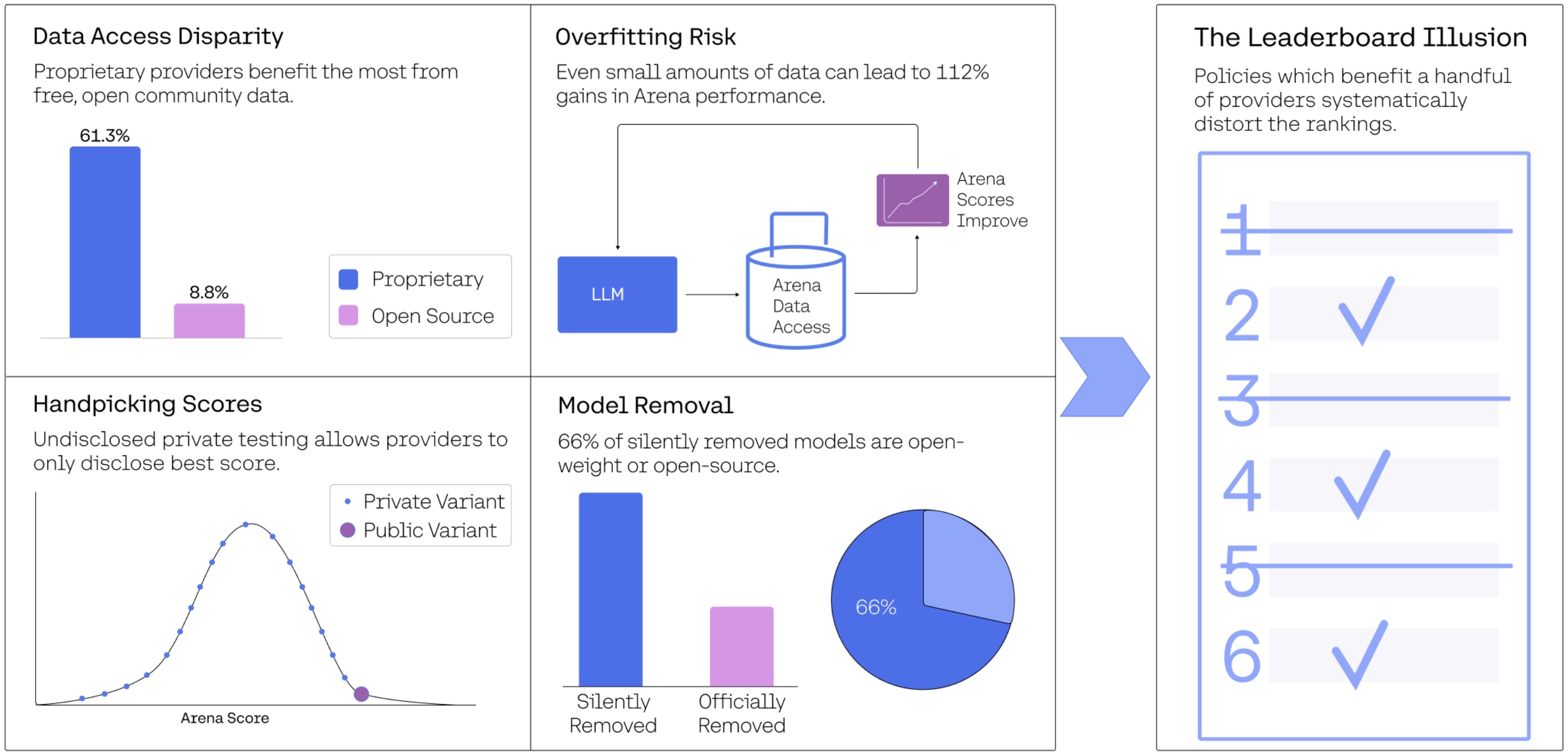
One of the most significant findings in the research is the existence of an undisclosed policy allowing select providers to test multiple model variants privately before public release. This practice gives these providers a substantial advantage: they can submit numerous models, see how they perform, and then choose to publish only their best-performing models.
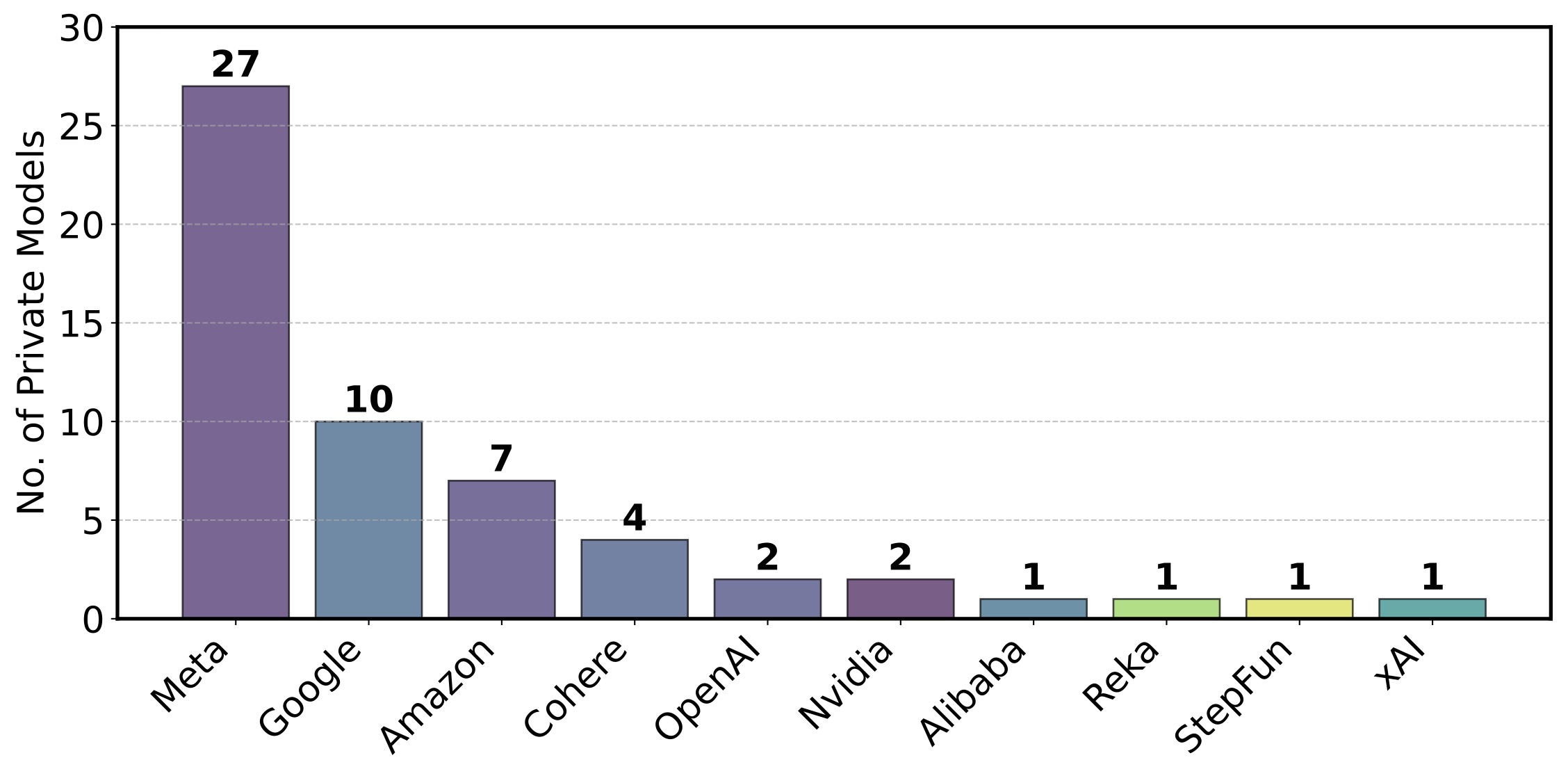
The researchers identified that certain model developers—most notably Meta, Google, OpenAI, and Amazon—have benefited extensively from this private testing arrangement.
In the most extreme case, Meta tested 27 different model variants on Chatbot Arena during a single month leading up to their Llama 4 release.
What makes this particularly troubling is that Chatbot Arena doesn't require all submitted models to be made public. There's also no guarantee that the version appearing on the public leaderboard matches what's available through the publicly available API. This creates a system where certain providers can cherry-pick their best results while hiding less impressive ones.
Data Access Disparity: The Rich Get Richer
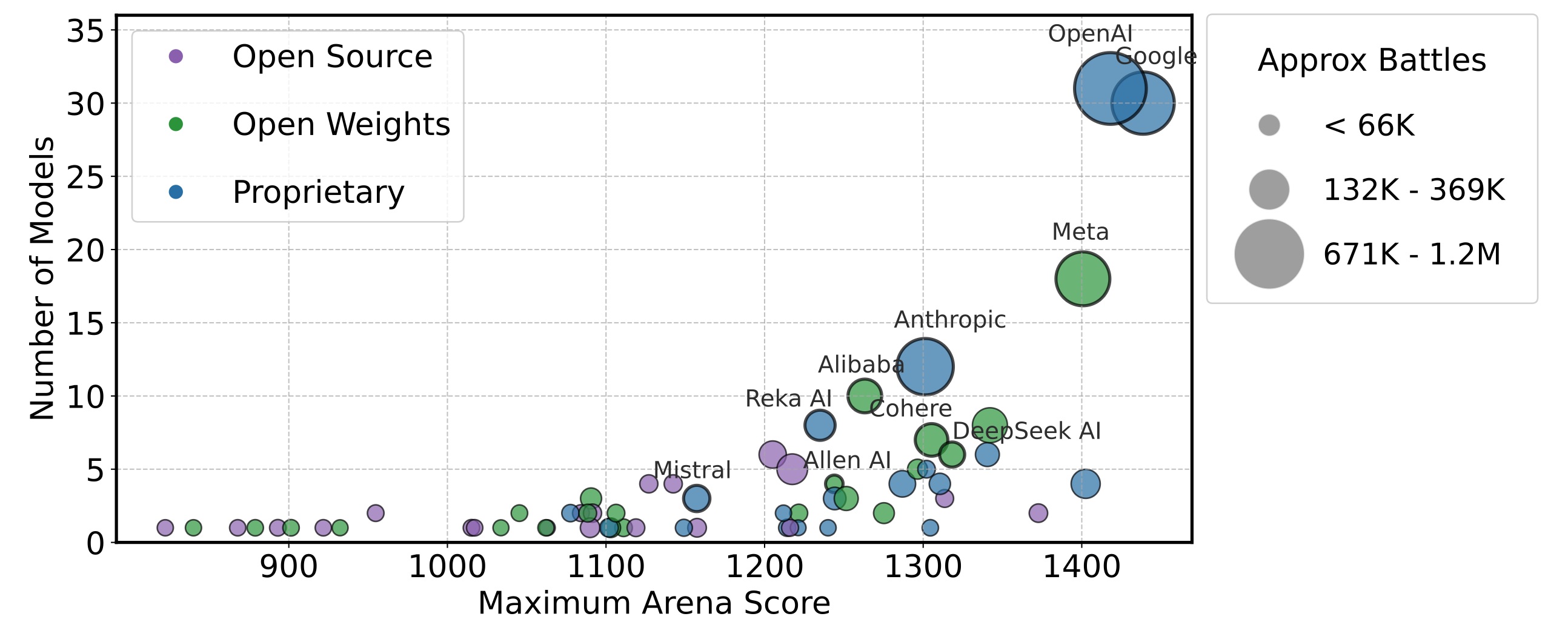
Chatbot Arena relies on crowdsourced feedback provided by everyday users. However, the research shows that proprietary model providers collect significantly more test prompts and model battle outcomes than open-source alternatives.
- Google and OpenAI have received an estimated 19.2% and 20.4% of all test prompts on the Arena, respectively.
- In contrast, a combined 41 fully open-source models have only received an estimated 8.8% of the total data.
- Proprietary models consistently received the largest share of data—ranging from 54.3% to 70.1% across different quarters.
This imbalance creates a "rich get richer" scenario: models with more data exposure can be better optimized for the Arena distribution, which further improves their performance and ranking.
The research demonstrates that access to Chatbot Arena data drives significant performance gains. In a controlled experimental setting, increasing the arena training data proportion from 0% to 70% more than doubled win rates from 23.5% to 49.9% on ArenaHard.
This finding is particularly concerning given the data access disparities between proprietary and open-source/open-weight models. If certain providers have disproportionate access to private API data, they can potentially yield even greater performance advantages—creating a feedback loop that further entrenches their dominance.
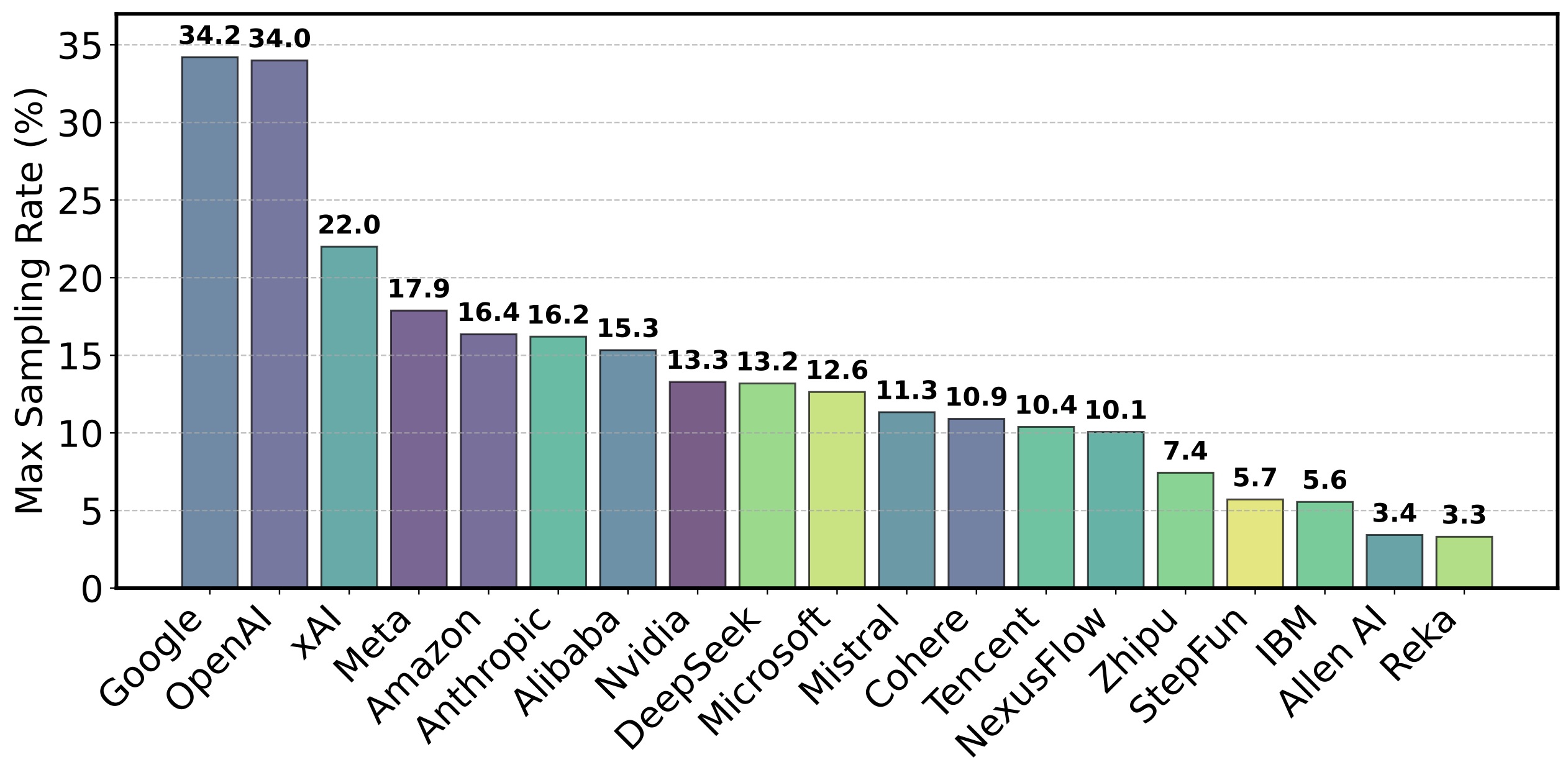
The research uncovers large discrepancies in sampling rates across providers. The sampling rate determines how often a model appears in battles and, consequently, how much feedback data the provider receives. Some providers enjoy substantially higher sampling rates than others:
- OpenAI and Google models have been observed with sampling rates up to 34%
- This is approximately 10 times higher than the maximum sampling observed for providers like Allen AI (around 3.4%)
These differences in sampling rates create yet another advantage for already-dominant proprietary model providers, as they receive more feedback data to refine their systems.
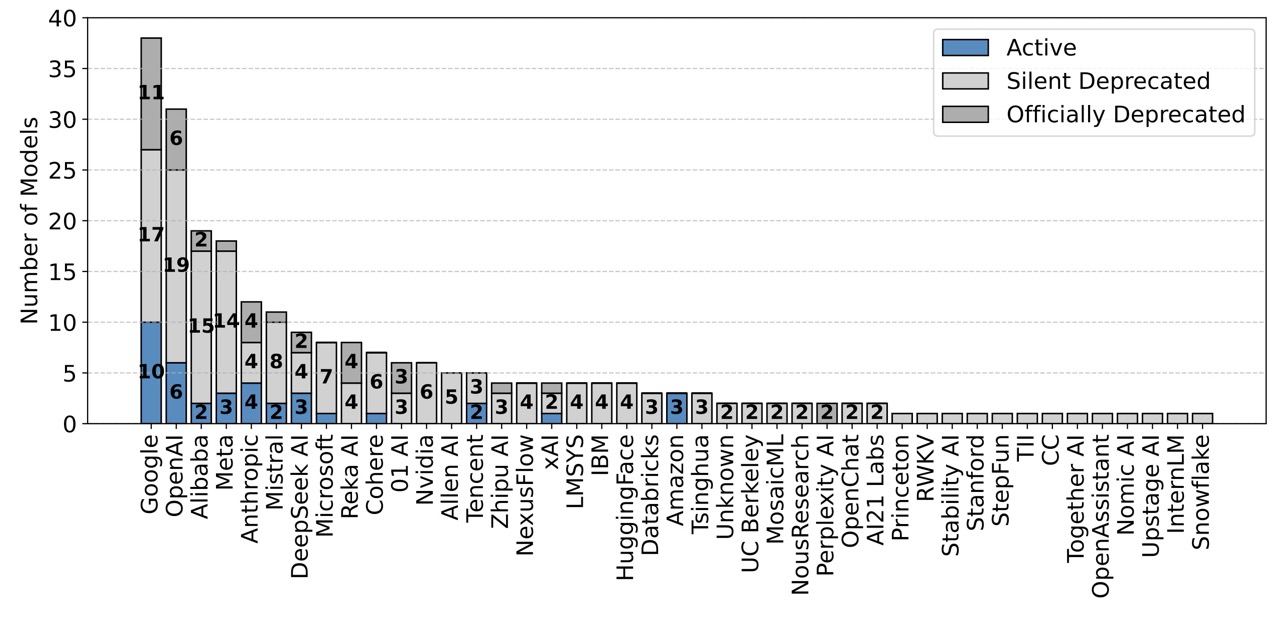
The Silent Deprecation Problem
Perhaps one of the most troubling findings is related to model deprecation—the process of removing models from active testing. Out of 243 public models examined, 205 have been silently deprecated without notification to providers. This is significantly higher than the 47 models officially listed as deprecated in Chatbot Arena's backend codebase.
This silent deprecation disproportionately affects open-weight and open-source models. Among the models that are silently deprecated, 66% are open-weight or fully open-source. When models are deprecated, they stop receiving new battle data, further exacerbating the data access disparity.
Chatbot Arena uses the Bradley-Terry model to calculate rankings based on win/loss outcomes. However, the research shows that current deprecation practices can violate key assumptions of this model, thereby reducing the reliability of the leaderboard rankings.
When models are removed from active testing without proper accounting in the scoring system, it creates distortions that make the rankings less trustworthy—particularly for open-weight and open-source models that face higher deprecation rates.
Recommendations to Restore Trust and Fairness
The researchers provide five actionable recommendations to restore fairness, transparency, and trust to Chatbot Arena:
- Prohibit score retraction after submission: All model evaluation results—including private variants—must be permanently published upon submission, with no option to retract or selectively hide scores.
- Establish transparent limits on private testing: Enforce a strict and publicly disclosed limit (e.g., maximum 3 model variants tested concurrently per provider) to prevent excessive testing runs that skew the leaderboard.
- Apply model removals equally: Ensure deprecation impacts proprietary, open-weight, and open-source models equally. For example, deprecate the bottom 30th percentile for each group.
- Implement fair sampling: Return to an active sampling method that prioritizes under-evaluated and high-variance pairs rather than favoring large proprietary providers.
- Provide transparency into model removals: Create a comprehensive, public list of all deprecated models to ensure the policy is implemented fairly.
The Way Forward: Balancing Competition and Collaboration
While the research highlights significant issues with Chatbot Arena, it's important to recognize that it originated as an academic-sponsored leaderboard that unexpectedly took on pronounced importance to the machine learning community. The organizers face considerable challenges in coordinating a fair and reliable evaluation platform.
Many of these issues likely emerged gradually as successive design choices and concessions to certain large providers accumulated. The research suggests reasonable interventions that could restore scientific accuracy and renew trust in the leaderboard.
True advancement in AI requires a level playing field where models are evaluated fairly based on their actual capabilities—not on who has privileged access to testing or data. By implementing the recommended changes, Chatbot Arena can continue to serve as a valuable benchmark while ensuring that all participants have an equal opportunity to showcase their innovations.
Research Paper:
The Leaderboard IllusionRecent Posts