geeky NEWS: Navigating the New Age of Cutting-Edge Technology in AI, Robotics, Space, and the latest tech Gadgets
As a passionate tech blogger and vlogger, I specialize in four exciting areas: AI, robotics, space, and the latest gadgets. Drawing on my extensive experience working at tech giants like Google and Qualcomm, I bring a unique perspective to my coverage. My portfolio combines critical analysis and infectious enthusiasm to keep tech enthusiasts informed and excited about the future of technology innovation.
4 Easy Ways to run DeepSeek R1 on your PC or Mac: Ollama, LM Studio, GPT4ALL, llamafile
AI Summary
You can run DeepSeek R1 on PC or Mac using Ollama, LM Studio, GPT4All, or llamafile, with varying model sizes ranging from 1.5B to 70B parameters and requiring different amounts of RAM. Running smaller models offers faster performance and lower system requirements.
March 21 2025 21:16
Running DeepSeek locally offers a fantastic opportunity to experiment with large language models right on your own machine. It's important to understand that DeepSeek comes in various forms: different base model sizes, distilled versions for efficiency, and quantized options to reduce memory footprint. By running it locally, you avoid the risk of sending your data to Chinese servers. Moreover, DeepSeek is particularly sensitive to questions about the Chinese government, but with local deployment, you have complete control to customize its responses. You can even configure it to provide answers that might otherwise be restricted or deemed inappropriate by certain regulations.
The crucial factor for local execution is your computer's RAM. You need enough RAM to load the entire model into memory. Model sizes vary significantly, starting with the relatively small 1.5 billion parameter (1.5B) model, which requires around 1.1GB of RAM. From there, the size increases with more powerful base models.
While the prospect of a massive 671 billion parameter (671B) model offering unparalleled capabilities is exciting, it also demands a substantial 404GB of RAM. If you're just exploring the capabilities of DeepSeek on your local setup, it's best to start with one of the smaller models that fits within your system's memory limitations. Don't expect to run the largest versions unless you have the corresponding hardware.
[Simplest] Use Ollama - MacOS, Ubuntu, Windows
[Powerful] Use LM Studio - MacOS, Windows, Linux
[Flexible] Use GPT4All - MacOS, Ubuntu, Windows
[SingleFile] Use llamafile - MacOS, Windows, Linux, FreeBSD, OpenBSD, and NetBSD
Benefits Running Deepseek R1 locally
Privacy & Security – Keeps data on your machine, avoiding third-party risks.
Speed & Offline Access – Faster responses with no internet required.
Cost Savings – No API fees or cloud compute costs.
Customization & Control – Fine-tune, optimize, and choose your backend.
Reliability – No downtime, always accessible, unaffected by server issues.
1) [Simplest] Use Ollama - MacOS, Ubuntu, Windows
Download Ollama and pull the manifest and configure the model to run. For the DeepSeek R1 Distill Qwen 1.5B model, it only took a few minutes (~1.1GB). It will even host a local API serving the model, if you need to call it from, say, Python.
ollama run deepseek-r1:1.5b
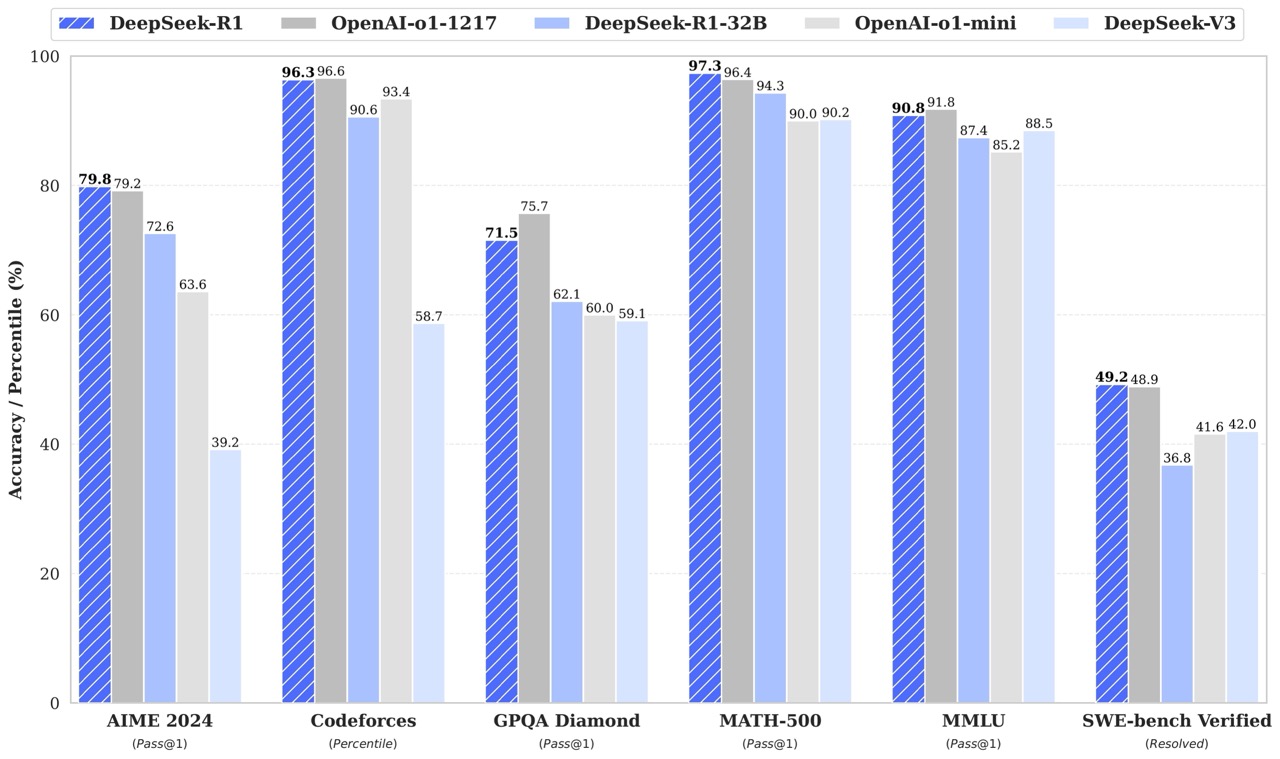
Below are the rest of the DeepSeek-R1 models created via fine-tuning against several dense models widely used in the research community using reasoning data generated by DeepSeek-R1. The evaluation results demonstrate that the distilled smaller dense models perform exceptionally well on benchmarks.
DeepSeek-R1-Distill-Qwen-7B (~4.7GB)
ollama run deepseek-r1:7b
DeepSeek-R1-Distill-Llama-8B (~4.9GB)
ollama run deepseek-r1:8b
DeepSeek-R1-Distill-Qwen-14B (~9GB)
ollama run deepseek-r1:14b
DeepSeek-R1-Distill-Qwen-32B (~19GB)
ollama run deepseek-r1:32b
DeepSeek-R1-Distill-Llama-70B (~42GB)
ollama run deepseek-r1:70b
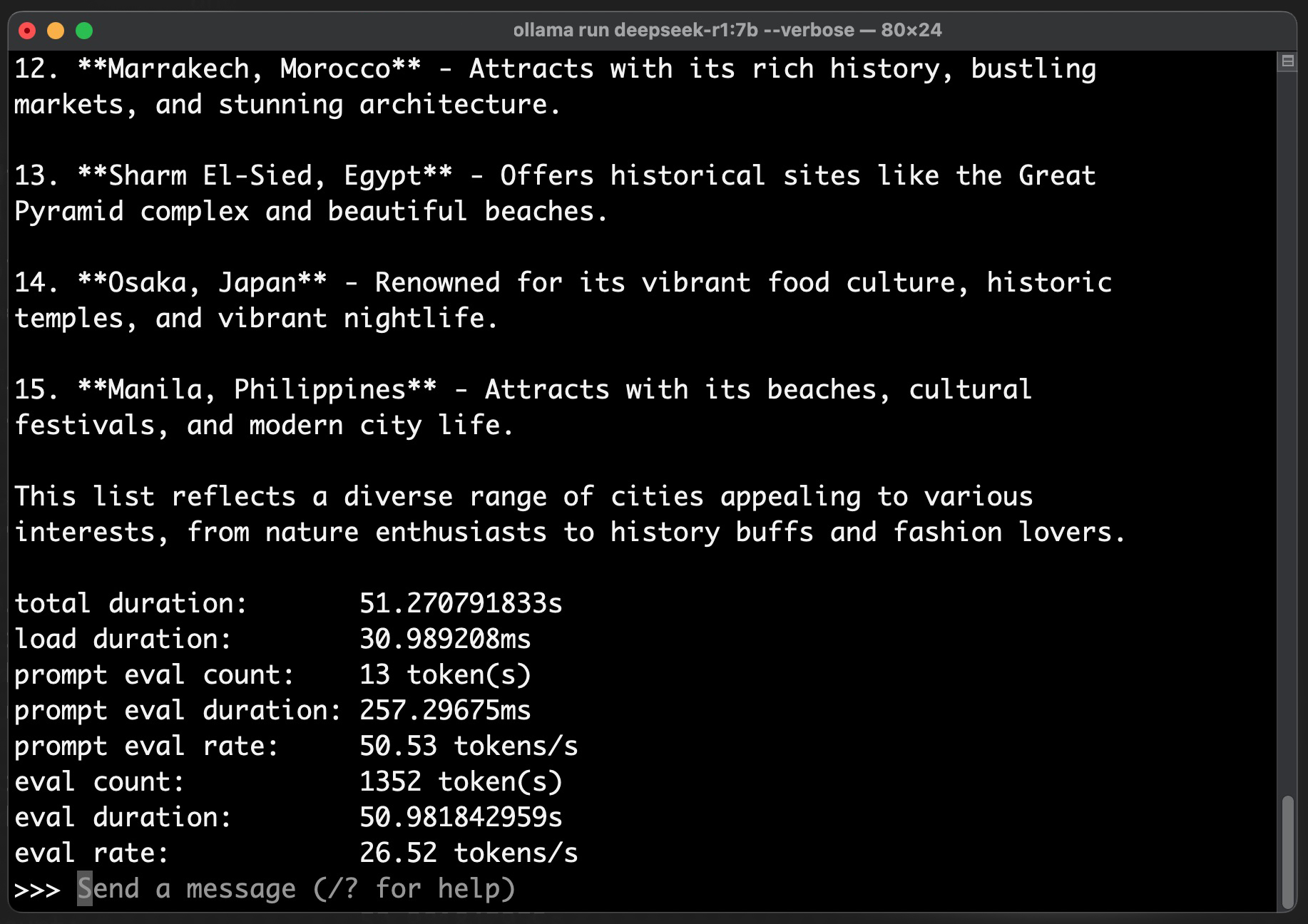
Running a prompt "Show me the list of most popular cities for tourist" using the DeepSeek-R1-Distill-Qwen-7B model on my M3 MacBook Pro with 18GB memory deliver a performance of 50.53 tokens/second. The same prompt using the smaller 1.5B model deliver 71.30 tokens/second. See result below:
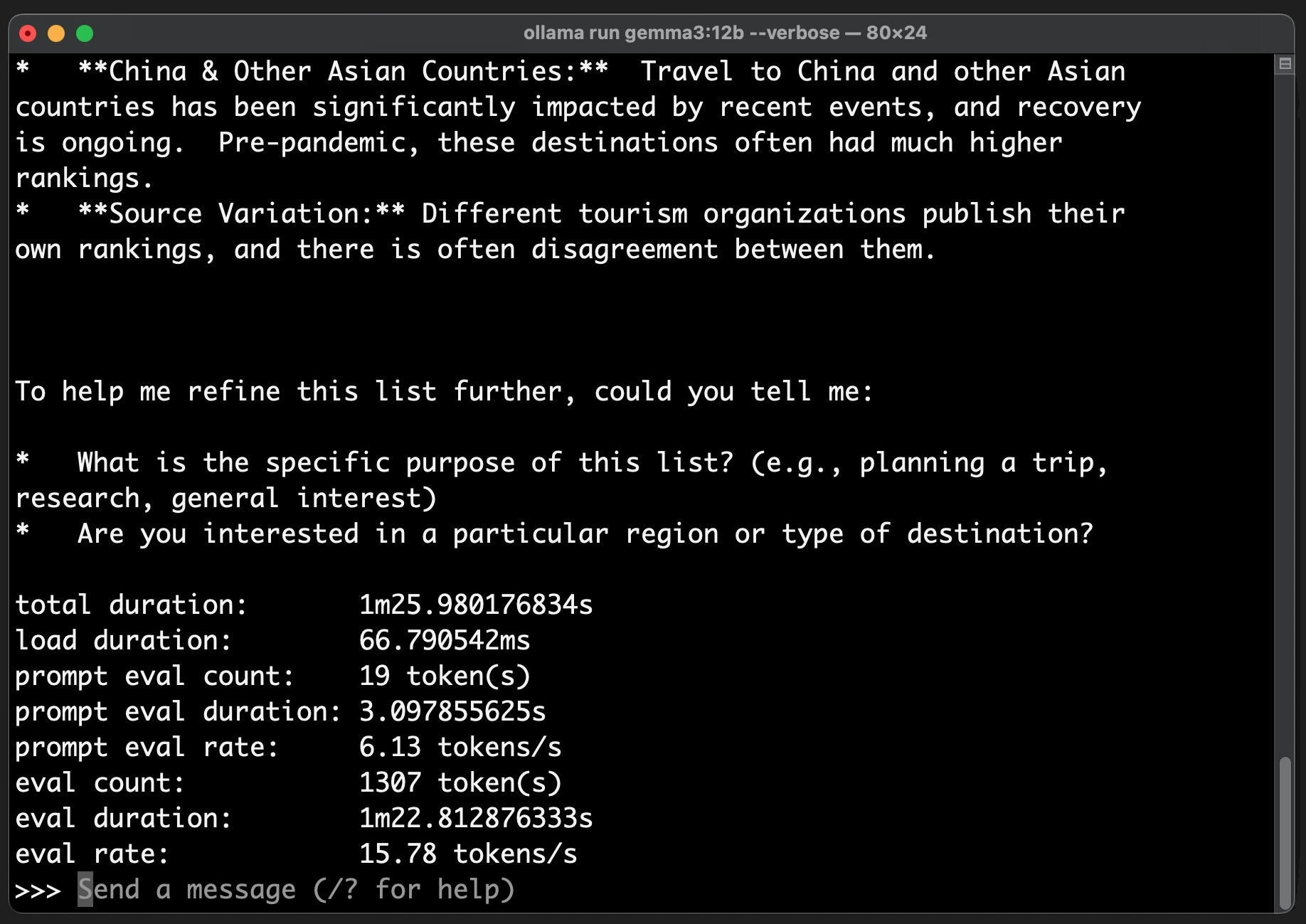
In comparison, running the latest Gemma 12B model from Google deliver a performance of 6.13 tokens/second.
2) [Powerful] Use LM Studio - MacOS, Windows, Linux
LM studio is a tool that you can use to experiment with local and open-source LLMs. You can run these LLMs on your PC/Mac/Ubuntu. There are two ways that you can discover, download and run these LLMs locally: Through the in-app Chat UI or OpenAI compatible local server. Here are the supported endpoints:
GET /v1/models POST /v1/chat/completions POST /v1/embeddings POST /v1/completions
After downloading from https://lmstudio.ai/ and installing LM Studio, open the application.
You can search "deepseek" and download the "DeekSeek R1 Distill (Qwen 7B)" or the "DeekSeek R1 Distill (Llama 8B)" models.
Navigate to the chat section on the left-hand side of the interface.
Click on "New Chat". At the top of the chat window, you should be able to select and load the model you want to use from a dropdown menu.
After selecting the model, you can start interacting with it by typing in the chat box that appears. Using the DeekSeek R1 Distill (Qwen 7B) model, I can get 24.34 tokens/second on my M3 MacBook Pro. RAM usage is 4.46GB and CPU utilization is around 4%-8%. See below LM Studio running DeepSeek R1 demo video for more details:
3) [Flexible] Use GPT4All - MacOS, Ubuntu, Windows
GPT4All is an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU. Note that your CPU needs to support AVX or AVX2 instructions. A GPT4All model is a 3GB - 8GB file that you can download and plug into the GPT4All open-source ecosystem software. GPT4All is optimized to run inference of 3-13 billion parameter LLMs on the CPUs of laptops, desktops and servers.
You can download the GPT4All installer from this website: https://gpt4all.io/
The file will be downloaded on your computer. Double click on the file and following the installation process. On a Mac, you should see the following screens during the installation process:
Open the GPT4All app and you should see a dialog box as shown below, allowing you to download the models, e.g. DeepSeek-R1-Distill-Qwen-7B model
After downloading the model, you can start the conversation just like in ChatGPT. You can also click on settings in top right corner to change the generation parameters. On my M3 MacBook Pro using the DeepSeek-R1-Distill-Qwen-7B model, I got about 26 tokens/second performance.
4) [SingleFile] Use llamafile - MacOS, Windows, Linux, FreeBSD, OpenBSD, and NetBSD
llamafile is a local LLM inference tool introduced by Mozilla Ocho in Nov 2023, which offers superior performance and binary portability to the stock installs of six OSes without needing to be installed. It has a web GUI chatbot, a turnkey OpenAI API compatible server, and a shell-scriptable CLI interface.
The magic of Llamafile lies in its ability to transform complex AI model deployment into a near-plug-and-play experience. By packaging the model, weights, and necessary runtime into a single executable, it dramatically reduces the technical barriers that often prevent developers from experimenting with advanced AI technologies. Key features of llamafile:
Runs across CPU microarchitectures: llamafiles can run on a wide range of CPU microarchitectures, supporting newer Intel systems using modern CPU features while being compatible with older computers.
Runs across CPU architectures: llamafiles run on multiple CPU architectures such as AMD64 and ARM64, and are compatible with Win32 and most UNIX shells.
Cross-Operating System: llamafiles run on six operating systems: MacOS, Windows, Linux, FreeBSD, OpenBSD, and NetBSD.
Weight embedding: LLM weights can be embedded into llamafiles, allowing uncompressed weights to be mapped directly into memory, similar to a self-extracting archive.
Single-File Distribution: Entire model and runtime are bundled into one executable, simplifying distribution and deployment
If you're using macOS, Linux, or BSD, you'll need to grant permission for your computer to execute this new file. (You only need to do this once) Run this command: "chmod a+x [filename]".