geeky NEWS: Navigating the New Age of Cutting-Edge Technology in AI, Robotics, Space, and the latest tech Gadgets
As a passionate tech blogger and vlogger, I specialize in four exciting areas: AI, robotics, space, and the latest gadgets. Drawing on my extensive experience working at tech giants like Google and Qualcomm, I bring a unique perspective to my coverage. My portfolio combines critical analysis and infectious enthusiasm to keep tech enthusiasts informed and excited about the future of technology innovation.
Vision-Language-Action Robotics Models from Microsoft, Google, Figure AI and NVIDIA
March 22 2025 08:49
The robotics field is witnessing a revolutionary transformation with the emergence of Vision-Language-Action (VLA) models. These advanced AI systems are bridging the gap between digital intelligence and physical world interaction, bringing us closer to the science fiction dream of truly versatile robots. This is a significant departure from conversational AI like ChatGPT, which primarily operates in the digital realm.
The core function of VLAs is to enable robots to comprehend instructions given in human language, visually assess their environment, and then generate the appropriate actions necessary to fulfill the given task. This fusion of vision, language, and action is not just an incremental improvement in AI; it is considered a pivotal step towards achieving Artificial General Intelligence (AGI). Recent developments from leading AI companies have produced remarkable breakthroughs in this space, with models like MAGMA, Gemini Robotics, Felix, and the newly announced NVIDIA Isaac GR00T N1 showcasing unprecedented capabilities in generalist robot control.
What are Vision-Language-Action
While Vision-Language Models (VLMs) can understand and generate content based on visual and textual inputs, VLAs take this a step further by incorporating action as a third modality. This means they can not only perceive and understand the world but also interact with it physically through robotic systems:
Vision: The vision component equips the VLA with the ability to "see" and interpret its surroundings. This is typically achieved through the use of vision foundation models, which act as vision encoders. These models are trained on vast amounts of visual data, allowing them to extract meaningful representations of the environment, including identifying objects, determining their pose and spatial relationships, and understanding the overall geometry of the scene. In essence, this component allows the robot to perceive and understand the objects and layout of its environment, much like a human uses their eyes to make sense of the world.
Language: The language component provides the VLA with the power to understand and process human language. This often involves the integration of large language models (LLMs), which have demonstrated remarkable capabilities in understanding natural language instructions and commands. This allows humans to communicate their intentions and tasks to robots in an intuitive and natural way, without the need for complex programming or specialized commands.
Action: The action component is what allows the VLA to translate its understanding of the visual environment and language instructions into physical actions. Based on the input from the vision and language components, the VLA generates appropriate actions to execute the given instructions. These actions can range from low-level motor commands, such as moving an arm or rotating its body, to high-level task planning, which involves breaking down complex tasks into a sequence of smaller, manageable steps.
To illustrate how these components work together, consider a simple scenario: a person asks a robot equipped with a VLA, "Bring me the red cup from the table." The robot would first use its vision system to scan the environment, identify the table, and locate a red cup among other objects. Its language processing capabilities would allow it to understand the instruction. Finally, the action component would enable the robot to plan and execute the necessary movements to navigate to the table, grasp the red cup, and bring it to the person. This seemingly straightforward task requires a complex interplay of perception, understanding, and action, all orchestrated by the VLA model.
Key Advances in VLA Technology
Recent months have seen several groundbreaking VLA models emerge, each pushing the boundaries of what's possible in generalist robot control:
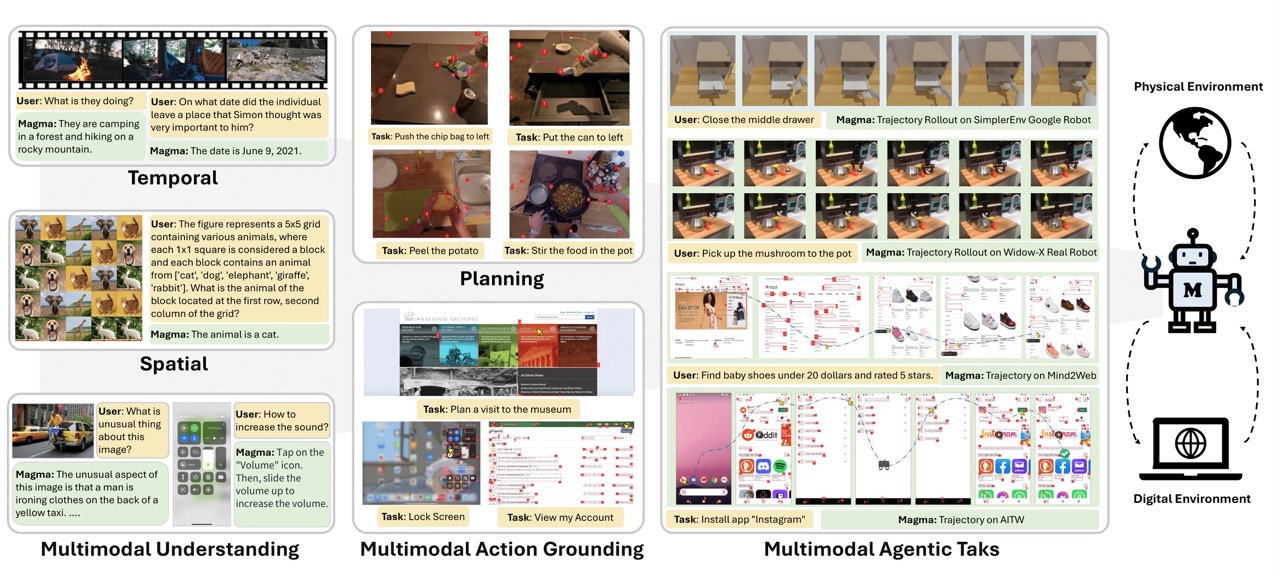
Microsoft's MAGMA: Bridging the Digital and Physical Worlds
Microsoft Research releases MAGMA, a multimodal AI foundation model designed to process information and propose actions across both the digital and physical realms, aiming to create AI agents that can serve as versatile, general-purpose assistants. MAGMA boasts a compelling set of features and capabilities. In the digital world, it can interpret user interfaces and suggest actions, such as identifying and clicking buttons within an application. In the physical world, it can orchestrate the intricate movements and interactions of robots.
A key strength of MAGMA is its ability to generalize effectively across different tasks and environments. The model can synthesize both visual and textual inputs to determine meaningful actions. MAGMA could enable a home assistant robot to learn how to organize a new type of object it has never seen or help a virtual assistant generate step-by-step instructions for navigating an unfamiliar software interface.
MAGMA has demonstrated strong zero-shot cross-domain robustness, meaning it can perform well on tasks and in environments it hasn't been specifically trained on. With efficient finetuning, MAGMA achieves significantly higher average success rates across various task suites. Notably, it performs competitively with, and sometimes even outperforms, state-of-the-art approaches on video understanding benchmarks, even without being trained on task-specific data.
Google DeepMind's Gemini Robotics: Bringing Multimodal AI to the Physical World
Google DeepMind has recently introduced Gemini Robotics, a new family of AI models built upon the foundation of Gemini 2.0. Gemini Robotics is an advanced vision-language-action (VLA) model that takes natural language and images as input and produces actions as output, enabling robots to physically move and perform tasks. The project centers around three core qualities essential for creating truly helpful robots: generality, interactivity, and dexterity.
The Gemini Robotics suite includes two primary models: Gemini Robotics and Gemini Robotics-ER (Embodied Reasoning). Gemini Robotics directly controls robotic movement, allowing for dexterous and responsive task execution. It leverages Gemini's robust world understanding to generalize to novel situations, handling new objects, diverse instructions, and unfamiliar environments, and has demonstrated performance more than double that of other state-of-the-art VLA models on generalization benchmarks. Built upon Gemini 2.0, it exhibits intuitive interactivity, understanding and responding to natural language commands in real-time and adapting to changes in its surroundings.
Gemini Robotics-ER is a specialized model focused on enhancing spatial understanding for robotics, significantly improving upon Gemini 2.0's capabilities in areas like object detection, grasping, and 3D spatial reasoning. It can autonomously determine how to interact with objects, such as figuring out the best way to grasp a coffee mug by its handle, and plan safe trajectories.
Gemini Robotics-ER excels at embodied reasoning capabilities including detecting objects and pointing at object parts, finding corresponding points and detecting objects in 3D. Google DeepMind is also prioritizing safety in the development of Gemini Robotics-ER, implementing a layered safety approach and introducing the ASIMOV dataset to evaluate and improve the safety of AI-driven robots.
Figure AI's Helix: A Leap Towards General-Purpose Humanoid Robots
Figure AI has recently unveiled Helix, a groundbreaking generalist Vision-Language-Action (VLA) model designed to control humanoid robots. Helix boasts several key features that distinguish it from previous approaches.
It provides full upper-body control, enabling high-rate continuous control of the entire humanoid upper body, including wrists, torso, head, and even individual fingers with 35 degrees of freedom operating at 200Hz. This level of dexterity allows for more human-like movements and coordination. Furthermore, Helix enables multi-robot collaboration, allowing two robots to operate simultaneously and work together to solve shared, long-horizon manipulation tasks involving objects they have never encountered before. One of the most impressive capabilities is the ability for robots equipped with Helix to "pick up anything", allowing them to manipulate thousands of unseen household objects simply by following natural language prompts.
Unlike previous methods that often required separate models for different tasks, Helix utilizes a unified neural network with a single set of weights to learn all behaviors, from picking and placing items to using drawers and refrigerators and even interacting with other robots, without any task-specific fine-tuning. Helix is running entirely onboard embedded, low-power GPUs (Nvidia Jetson Orin modules consuming under 60W), making it suitable for immediate real-world deployment with reduced latency and without reliance on external cloud computing.
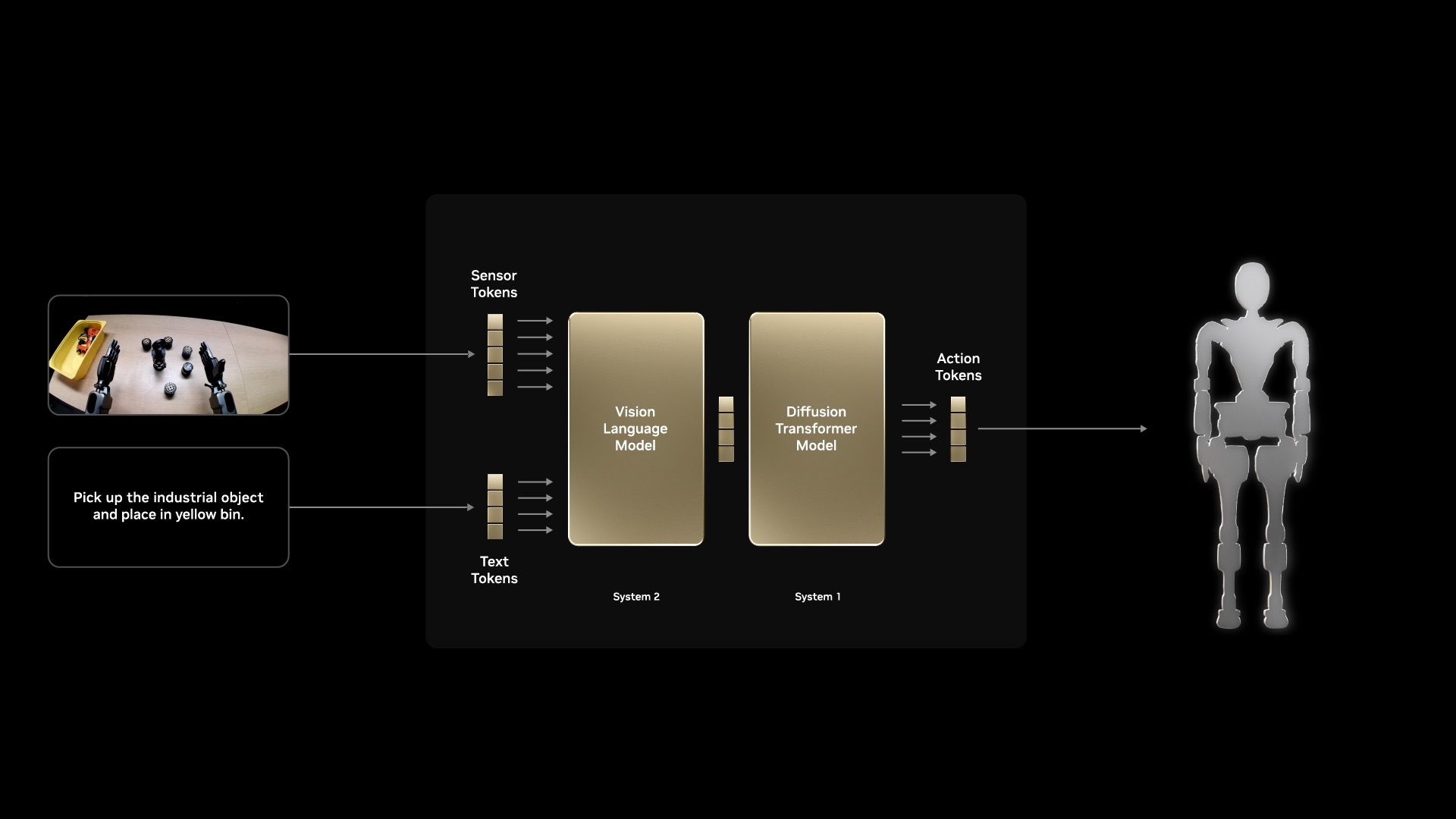
NVIDIA's Isaac GR00T N1: The First Open Humanoid Robot Foundation Model
NVIDIA has recently unveiled Isaac GR00T N1, the world's first open, fully customizable foundation model for generalized humanoid reasoning and skills. Released in March 2025, GR00T N1 represents a significant leap forward in humanoid robot development and is the first in a family of models that NVIDIA plans to pretrain and release to robotics developers worldwide. GR00T N1 features a dual-system architecture inspired by principles of human cognition:
System 1: A fast-thinking action model that mirrors human reflexes or intuition
System 2: A slow-thinking model designed for deliberate, methodical decision-making
Powered by a vision language model, System 2 reasons about the environment and received instructions to plan actions. System 1 then translates these plans into precise, continuous robot movements. The model is trained on human demonstration data and massive amounts of synthetic data generated by the NVIDIA Omniverse platform.
GR00T N1's key capabilities include generalizing across common tasks such as grasping, moving objects with one or both arms, transferring items between arms, and performing multistep tasks requiring long context and combinations of general skills. These capabilities can be applied to various use cases including material handling, packaging, and inspection.
A key advantage of GR00T N1 is its open and customizable nature. Developers and researchers can post-train the model with real or synthetic data for their specific humanoid robot or task. Leading humanoid developers with early access include 1X Technologies, Agility Robotics, Boston Dynamics, Mentee Robotics, and NEURA Robotics.
VLAs in Action: Real-World Applications Across Industries
The potential applications of Vision-Language-Action Models span a wide array of industries, promising to revolutionize how we interact with technology and automate tasks in the physical world.
Robotics and home assistance: VLAs are enabling humanoid robots to perform everyday household chores like folding laundry or fetching items, making them potential companions and helpers for the elderly or individuals with disabilities. Figure AI's Helix, for example, has demonstrated its ability to collaboratively store groceries and manipulate various household objects based on natural language instructions. Google DeepMind's Gemini Robotics also holds promise for assistive robotics, capable of understanding and responding to diverse instructions for daily tasks.
Industrial automation and manufacturing: Robots capable of handling irregularly shaped or fragile items, adapting to changes in production lines without the need for extensive reprogramming, and performing quality control through visual inspection and precise manipulation. Gemini Robotics has already been tested in manufacturing settings for assembling components with high accuracy.
Healthcare: VLAs could empower robots to assist nurses and doctors with tasks such as fetching supplies, monitoring patients, and even aiding in delicate surgical procedures requiring fine motor skills. Gemini Robotics' dexterity could prove particularly useful in such applications.
Logistics and warehousing: Models like Figure AI's Helix and NVIDIA's GR00T N1 are being developed for package manipulation and triage in logistics environments, with the potential to adapt to changes in inventory layout and collaborate with human workers.
Disaster Response: Robots equipped with these models could navigate through rubble, search for survivors, and deliver essential supplies in hazardous and inaccessible areas.
Automotive industry: Leverage VLAs to enhance perception in autonomous vehicles, enabling them to better understand complex traffic situations by combining visual data from cameras with textual information from maps and traffic signs, leading to safer navigation. Furthermore, AI agents powered by VLMs (a precursor to VLAs) can analyze road inspection videos to identify hazards, and in the future, VLAs could potentially automate the generation of maintenance reports and even trigger repair actions.
Gaming and virtual environments: AI agents that can interact with the world and users more naturally. Models are being developed to create 3D autonomous characters with social intelligence, capable of perceiving, understanding, and interacting with humans in immersive virtual settings.
Search engines and information retrieval: The underlying technology of VLMs (and by extension, VLAs) is being used to improve search results by understanding the context of both visual and textual queries. This could lead to future applications where VLAs perform actions based on retrieved information.
Challenges and the Path Forward: What's Next for VLAs?
Despite the remarkable progress in VLA models, several challenges remain that need to be addressed for their widespread adoption in complex real-world scenarios.
Limited generalization is a significant hurdle, as models trained on specific environments or tasks often struggle to perform well in unseen situations.
The complexity and scalability of these models also present challenges, with complex architectures requiring substantial computational resources for both training and inference, making deployment on edge devices difficult.
Data scarcity, particularly the collection of diverse and high-quality real-world data, remains a bottleneck for training robust VLA models.
Ensuring effective cross-modal alignment between visual and language information is crucial, and models can sometimes struggle with this, leading to inaccuracies or even hallucinations in generated responses.
Tasks requiring precision manipulation in dynamic environments can also be challenging for current VLA models.
Ethical considerations are paramount as these technologies become more advanced and integrated into our lives. Bias in training data can lead to harmful label associations and unfair outcomes.
Privacy concerns related to data collection and the deployment of robots in personal spaces need careful consideration.
Ensuring the safety and reliability of autonomous robots operating in the real world is also critical, as is addressing the potential for misuse of this powerful technology.
Looking ahead, future research directions aim to tackle these challenges. This includes developing more efficient and diverse data collection methods to overcome data scarcity. Improving model efficiency to reduce computational costs and enhance scalability is also a key focus. Enhancing cross-modal alignment to ensure better integration and understanding of visual and language information is another critical area. Researchers are also actively exploring and improving the zero-shot capabilities of VLAs to enable them to handle unseen environments and tasks more effectively. Finally, proactively addressing the various ethical concerns associated with VLA models is essential for responsible development and deployment.
The Transformative Potential of VLAs
Vision-Language-Action models represent a monumental leap forward in the quest for truly intelligent and helpful robots. The ability to seamlessly integrate visual perception, natural language understanding, and the capacity for action is unlocking a future where robots can interact with our world in meaningful and intuitive ways.
The progress made by pioneering models like Microsoft's MAGMA, Google DeepMind's Gemini Robotics, Figure AI's Helix, and NVIDIA's Isaac GR00T N1 is bringing us ever closer to this reality. While challenges remain, the rapid pace of innovation in this field is undeniable.
As these models continue to evolve and mature, we can anticipate a profound impact on various aspects of our lives, from the automation of mundane tasks to the creation of sophisticated robotic assistants that can enhance our productivity, safety, and overall well-being. The journey towards robots that can truly see, understand, and act is well underway, and the possibilities that lie ahead are nothing short of transformative.